
資料工程師的煩惱 — 如何選擇檔案格式,讓資料處理更有效率 & 如何利用 Kaggle 提升 Machine learning Engineer 的軟實力?
活動主辦單位:Taiwan Data Science Meetup 台灣資料科學社群

塔圖科技簡介
塔圖科技是成立超過10年的數位廣告公司,專注於透過新技術提升廣告成效,作法為透過跨國跨螢幕追蹤使用者,塔圖科技的Data Team每天要處理近三千萬筆的使用者事件資料,提供的服務包含多種廣告渠道投放、預測受眾包,還有提供廣告自動化工具。
主題一:資料工程師的煩惱 — 如何選擇檔案格式,讓資料處理更有效率
講者介紹:詹鎧維,目前任職於塔圖科技,擔任機器學習工程師,主要任務為使用蒐集到的使用者行為, 來建構模型預測各種不同主題。
大綱
- 主題介紹
- 常見檔案格式
- 實驗比較
- 結論
1. 主題介紹
資料科學家在工作上會遇到以下三種情境:處理資料、儲存資料、讀取與寫入資料。在現在被數據包圍的時代,資料會以影片、文本、圖像、表格等格式存在,我們常碰到要處理的資料型態包含Boolean (布林值)、Float (浮點數)、Int (整數)、String (字串)等。在儲存資料方面,我們會把資料儲存在雲端或者本機,並且希望這些資料不要佔用太多的硬碟空間,這樣也利於快速傳輸這些資料。在讀取與寫入資料的部分,其實怎麼樣讀寫資料差很多,不同檔案格式在儲存資料時的機制其實也有很大的差異,像是有基於Row (列)的儲存格式和基於Column (行)的儲存格式在讀取以及寫入的速度上就有很大的不同。
一直一段時間以來,我們都在使用CSV文件格式來儲存表格式的資料,實務上常遇到像是檔案過大,導致無法存放,或者檔案讀寫太慢,導致程式運行時間看不到終點,難道我們只能靠增加硬碟空間以及提升自己的硬體設備來解決這些問題嗎?
2. 常見檔案格式
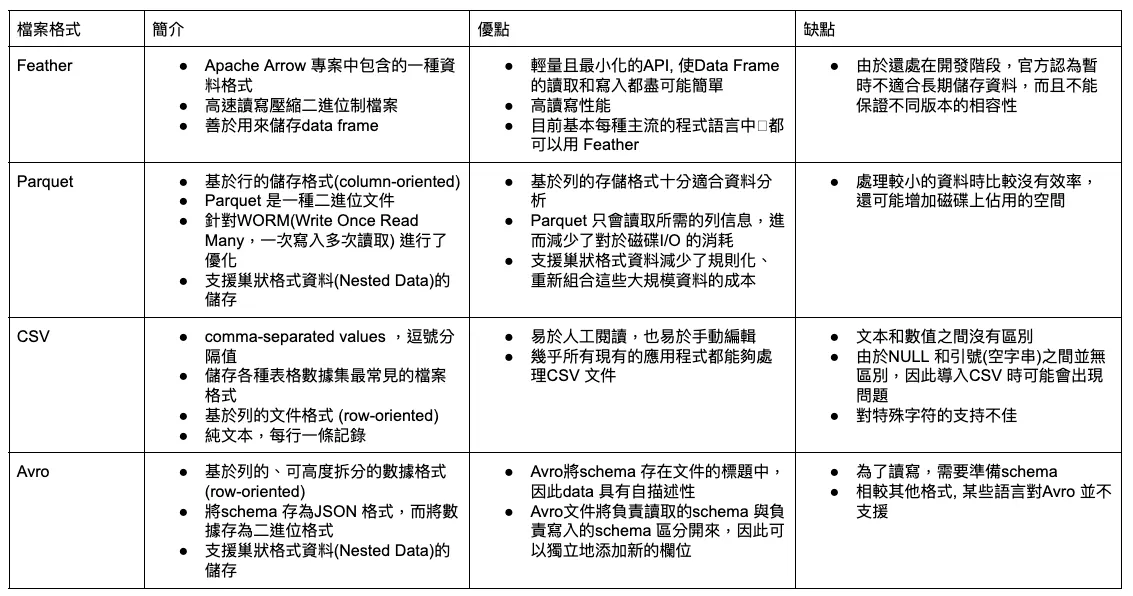
這邊介紹在塔圖科技Data Team四種常見的檔案格式:Feather、Parquet、CSV、Avro,最主要因為塔圖科技主要使用Google Cloud Platform所提供的BigQuery還有Google Storagen所支援的四種格式。
四種檔案的簡介以及優缺點整理如下:
3. 實驗比較
這次透過由實驗來觀察各個儲存格式在處理不同的資料型態時,在讀取效率以及資料佔用空間大小的差別,實驗設置有總共五個資料集,每組資料集有500,000 Rows、100 Columns,包含四個只有單一資料型態的資料集(Boolean、Float、Int、String) 以及一個混合資料型態的資料集(Mixed,各個資料型態都佔25%),然後透過以下兩種Libaray:Pandas和Datatable來進行測試。
資料集一:全部資料為布林值 (Boolean),從下圖可以看到,讀取以及寫入最快的都是Feather,而花費最少儲存空間的為Parquet。
(左圖為讀取寫入速度比較、右圖為檔案儲存空間比較)
資料集二:全部資料為浮點數 (Float),從下圖可以看到,讀取以及寫入最快的一樣是Feather,而花費最少儲存空間的為Avro。
資料集三:全部資料為整數 (Int),從下圖可以看到,讀取以及寫入最快的依舊是Feather,而花費最少儲存空間的也還是Avro。
資料集四:全部資料為字串 (String),從下圖可以看到,讀取和寫入最快的以及花費最少儲存空間的都是CSV。
資料集五:混合資料型態 (Boolean、Float、Int、String各佔25%),從下圖可以看到,讀取最快的是Feather,寫入最快的為CSV,花費最少儲存空間的都是Avro。
下表為實驗資料集的總結表格,我們可以看到在讀取以及寫入速度的方面,Feather表現較佳,而在儲存空間的部分,Avro則較有優勢。
接著來看這些檔案格式實際應用在塔圖科技的例子,任務案例一 (3,155,535 rows、2 columns、String字串資料型態、沒有巢狀格式資料),這個資料其實是在專案中的一小部分,主要任務是需要將此資料集做整理後上傳到Google Storage做存放並且等待下一個階段來使用。從下圖可以看到讀取以及寫入速度最快的是CSV,但是看到儲存成本時,Feather檔案格式則佔據了最小的容量 (CSV佔據最多容量),所以在評估這些因素後,塔圖科技的Data Team最後決定使用Feather這個檔案格式。
任務案例二 (2,695,925 rows、6 columns、String字串資料型態、有巢狀格式資料),這個任務是在BigQuery上做完查詢後,直接將結果匯出到Google Storage上。雖然一樣從下圖可以看到讀取以及寫入速度最快的是CSV、花費最少儲存空間的為Feather,但由於兩種檔案格式都不支援巢狀格式資料,塔圖科技的Data Team最後決定使用Avro這個檔案格式。
(其實Feather和CSV是不支援巢狀格式資料,這邊的比較是先將Avro的檔案讀成DataFrame的形式,再將它存成Feather或CSV檔案格式,以便比較)
4. 結論
- 不同的任務需求,所適合的檔案儲存方式以及邏輯也是會有所不同。最後在挑選檔案格式時,還是要看在執行專案時,有比較多的讀取以及寫入或者是特殊的資料型態 (例如巢狀資料格式)。
- 數據量到一定的程度後,讀寫的速度以及儲存的成本也會有非常大的差異。
主題二:如何利用 Kaggle 提升 Machine learning Engineer 的軟實力?
講者介紹:饒宗翰,目前任職於塔圖科技,擔任機器學習工程師,主要工作為預測消費者在電商的行為, 喜歡接觸來自不同領域的機器學習相關題目。
大綱
- Kaggle 是什麼?
- 塔圖科技資料團隊在做什麼?
- 怎麼找出合適的比賽?
- Tabular Playground Series
- 打一場 Kaggle 的流程
- 如何將 Kaggle 裡的技能應用到工作上?
1. Kaggle 是什麼?
Kaggle是一個資料競賽平台,平台提供各種資料集以及競賽,同時也提供虛擬機器有建置好的環境以及足夠的資源讓大家去做資料分析或者模型預測,參賽者也會將他們所使用的Code分享出來和大家一起互相交流、學習,也有公開的討論區可以提問。 另外,Kaggle也有提供教學課程給剛加入的使用者,讓他們快速了解Kaggle或學習資料科學。其他類似Kaggle的平台如下
- SIGNATE (日本的平台,多為日本國內企業或政府所舉辦的競賽)
- TopCoder (程式編寫競賽平台,但也有數據分析比賽)
- 其他台灣的資料競賽平台
- Aldea 人工智慧共創平台
- AI 實戰吧
- 全國智慧製造大數據分析競賽
2. 塔圖科技資料團隊在做什麼?
塔圖科技主要做數位廣告投放,所以資料的內容大多是消費者在電商平台上行為事件,主要為表格式資料、時間序列資料,而主要任務為建立預測模型,預測內容包含買或不買 (二元分類)、消費頻率 (迴歸分析)、電商銷量 (迴歸分析)等。
3. 怎麼找出合適的比賽?
在了解實際場景應用後,大家就可以到Kaggle的平台上找出類似或相關的競賽,然後從Kaggle競賽中去學習,並將學到的知識用於平常工作上。Kaggle大致上有兩種分類比賽的方法:比賽任務、資料庫:

大家可以利用這些類別去快速在Kaggle平台上搜尋到適合自己的比賽,這些類別會以標籤的形式出現在Kaggle競賽裡。下圖競賽為美國運通想預測他們的使用者會不會欠款,依照分類,它就會是二元分類、表格資料的競賽。除了這些類別,大家也可以看到有很多其他的標籤,例如題目領域以及資料集大小。
除了比賽的標籤以外,先前提到參賽者會把Code分享出來的筆記本 (類似Jupyter Notebook的形式)也會有標籤讓大家方便收尋,標籤包含受眾、分析目標、機器學習技術、演算法等,所以大家也可以標籤來去找尋想學習的模型或技術。
4. Tabular Playground Series
Kaggle針對表格資料每個月都會舉辦競賽 (Tabular Playground Series),每次的競賽目標也會不同,舉2022年9月的競賽為例,此次資料集提供6本書在4個不同國家的過去銷售量,然後競賽目標是要預測每本書在每個國家的未來銷售量,剛好在這場競賽中就可以學習到一些方法可以應到塔圖科技的實際案例。
5. 打一場 Kaggle 的流程
1. 探索資料庫 (Exploratory Data Analysis): 在剛進入一個比賽時,我們不會馬上拿到資料就開始建預測模型,通常第一步都是要從探索資料集開始,包含了解資料分布,檢查資料中是否有離群值,或者看看各個特徵 (Feature)以及標籤是否有是否有什麼樣的關聯性,以及透過視覺化來找尋資料的特性。
2. 特徵工程 (Feature Engineering): 在了解完資料後,你就可以利用前一步所了解的特性來去做特徵工程以及資料清洗的步驟,像是填充缺失值 (Missing Values)、正規化 (Normalization)、類別資料處理 (One-Hot Encoding)等,並將資料整理成後續建立模型比較方便的格式。
3. 建立模型 (Build Model): 接下來就進入到建立模型的步驟,這邊講者提供了一個在scikit-learn上的選用模型流程圖供大家參考 (官網連結),可以利用這個流程圖去比較有系統性的找到合適的模型。
4. 驗證模型 (Validate Model): 下一步就是根據該場次競賽所提供的指標來去驗證你的模型,常用的指標包含 MSE (Mean Square Error)、MAP 、RMSE (Root-mean-square Error)等、驗證方法包括Hold-Out、Cross Validation、Leave-One-Out等。
- Hold-Out:常見的把Validate set分出來後另外驗證metrics
- Cross Validation:將資料及分成K的子集,每次訓練使用K — 1個子集的集合當作訓練集並驗證在剩下的資料集上,訓練K次後結果取平均來看模型的能力,通常用在小資料集上,因Kaggle資料集大小通常比較有限,因此也是Kaggle最常見的驗證方式。
- Leave-One-Out:主要方式是在多分類題目中,把訓練難度比較大的小類別排除後看整體平均準度的驗證方式。這是在Kaggle上比較不常見的形式,比較常出現在實際場景。
5. 調整參數 (Hyper Parameter): 有模型跟指標後,就到調整參數的步驟,以往的話大部分都是建模的人手動去調整參數,現在有越來越多套件可以幫忙調整參數,建模的人可能只要提供不同參數的範圍 (Range),這些套件就能找到什麼樣參數的排列組合能達到最佳模型。
- XGBoost的tuning套件 (連結; 另外Note on Parameter tuning不是套件:只是官方文件說明有哪些參數可以調整:連結)
- LGBM的Tunuing套件 (連結)
- NN的Tuning套件 (Hyperopt)
- 結合Keras的案例 (連結)
6. 多個模型投票 (Ensemble): 最後還可以有一個步驟,當你有不同的模型時,你可以將多個模型預測值去平均或投票來產出最後預測結果,這樣有時候會帶來更好的模型表現。
6. 如何將 Kaggle 裡的技能應用到工作上?
最後來看講者是如何將表格資料競賽 (Tabular Playground Series)學習到的知識應用到實際的工作上,這個舉的例子是預測某家電商公司銷售量,主要使用2021年7月到2022年7月一整年的資料來去預測2022年8到9月的銷量。這個資料集只有時間跟銷售量兩個資料,在探索資料時原本只能想到可以畫趨勢圖,但從Kaggle競賽中學習到不用局限於手中的資料,也可以利用外部資訊。
第一個例子像是holidays這個套件能列出各國家的國定假日,這樣一來就看出國定假日對於銷量的影響 (像是假期一過銷量就下降等),並可以新增加特徵例如這一天是不是國定假日或是這一天距離下一個國定假日有多少天。
第二個例子,購買量可能跟當時的大環境有關,所以也可以利用套件把GDP、當時油價、金價加入特徵,去看能不能幫助模型預測。
第三個例子是講者看到比較特別的方式,利用Periodograme去看在時間區間長短中銷量的變化性,藉此判斷時間區間對銷量的影響程度,這樣有利於我們去選時間的精度。
第四個例子,因為銷量是一個有循環性的決策過程,我們可以用權重乘上Sin與Cos的餘弦函數跟正弦相位移疊加來表達,在調整權重之後,讓曲線盡量趨近原本的的銷量曲線,這樣就能模擬出在正常情況下銷售量應該大概是多少,這個模擬的銷量也可以加入模型來進行預測。
最後這可以將所有以上提到的資訊整合再一起去建立模型,左圖是沒有使用Kaggle上學習到的特徵所訓練出的模型,而右圖是有使用Kaggle上學習到的特徵所訓練出的模型,從圖和指標都可以看出來模型表現有提升。
7. 結論
- 將自己工作的題目整理好類別,在 Kaggle 上一定可以找到類似的題目
- 除了時間序列資料表格的比賽外,還有很多類型的比賽可以參考
- 能夠與全世界的 Data 工作者們交流,遇到問題不用害羞,直接問作者
- 即使只是做 EDA 的文章,依然可以幫助我們得到關於 Feature 的啟發
- 看到好文章也不要忘記為作者點讚喔
筆記手:Jason Wang
校稿:詹鎧維、饒宗翰
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!