
NVIDIA 加速資料科學
利用 Rapid 套件實現 GPU 加速 Spark
講者簡介

Andrew 目前在輝達(NVIDIA)擔任資深資料科學家,同時也是深度學習機構(Deep Learning Institute; DLI)國際認證講師,所領導開發的工業瑕疵檢測工作坊在全世界已被數十個國家與客戶所使用。
主要任務為協助客戶運用NVIDIA的運算平台建立創新解決方案,協助的客戶包含台灣各家醫學中心的智慧與精準醫療應用,近期更與三軍總醫院協同全球20家醫學中心利用聯邦式學習技術打造跨國 AI COVID-19 模型,另外亦協助全球製造業與半導體商等客戶在瑕疵檢測與自動瑕疵分類(Automatic Defect Classification; ADC)的應用與優化開發上。
原直播連結:點此觀看
2023/03/20–03/24 GTC 大會議程推薦
進入主題之前 Andrew 先跟大家分享 NVIDIA 將於 2023/03/20–03/24(Time zone: Taiwan)舉辦整年度最大的線上會議:GTC(GPU Technology Conference),共有 650 場免費的Session可以報名參加(點此報名)
除了分享 NVIDIA 的各種軟硬體解決方案之外,也包含台灣或全球跟客戶POC的案例分享,以下是 Andrew 推薦的幾個議程:

- 打造新一代人工智慧系統:NVIDIA 接下來的策略會往軟體發展,此議程中會介紹 NVIDIA 推出的 Enterprise license 的解決方案
- 實際導入人工智慧模型,使用 Triton 推論伺服器加入:Triton 是 NVIDIA 一個類似 tensorflow servering 機制,這跟資料科學領域非常相關,因為資料科學的模型最終還是需要上線服務,不管你是用 Scikit-learn 或是其他 deep learning 的 model,都可以使用 Triton 在 NVIDIA 所有產品上運作。這個議程中會說明 Triton 如何透過硬體軟體整合改善整個 inference 的 throughput(吞吐量)、 latency(延遲)、或是處理 video stream 時提升 frame per second(每秒幀數)。
- 透過產生合成資料進行大量 EUV 遮罩檢測:會分享如何與 TSMC(台積點) 合作,使用 GPU 做光罩瑕疵檢測的技術突破
- 為 Hopper 架構最佳化的應用程式:在此議程中會介紹 Hopper 新一代的硬體,並分享 Hopper 特殊指令集如何加速近期最熱門 ChatGPT model 的訓練。

- 如何有效率地建立及部署大型語言模型?:台灣在過去比較沒有那麼積極發展超大語言模型,Andrew 自己觀察到是幾個月前 huggingface 跟法國機構一起用 384 張 A100 訓練 3 個月的時間,裡頭包含了multilingual 包含了 github…各種語言。重點這個結果是 opensource,Andrew 認為在這個 community 裡 opensource 很重要,因為如果什麼東西都要收錢,整個研究發展會相對慢。而台灣看到這波趨勢後,不只學校,很多企業都想投入大型語言模型的訓練,所以 NVIDIA 跟 TWS(台灣智慧雲端)、國家高速網路中心在這方面有些合作,這個議程幫助想瞭解 NVIDIA 在 SDK、Platform、硬體…等層面協助有效率的建立及部署ㄒ大贏語言模型
- 如何建構雲端運算為下一波應用程序注入強大動能:如果想瞭解 NVIDIA 如何從 single GPU 走到 Platform,如何利用 networking 的 switch 甚至軟體加值,讓整個 platform 更有效率,可以參加這個分享

最後還有兩個DLI實作課程:課程中會使用 jupyter lab 讓參與者在線上實際參與整個 cooding 過程。
最後提供一些 developer program,有興趣的人歡迎掃描 QR Code 報名

開發者使用 Rapid,降低「GPU 加速 Spark」的學習門檻
一開場 Andrew 先介紹什麼是Spark?Spark 跟 Hadoop、Hive 相同,都是用於 scale out 的套件。Spark 過去是利用 CPU Node 來加速運算,而 NVIDIA 希望能在 big data 的運算節點都插上一兩張 GPU。

據 Andrew 了解台灣企業可能會有上百顆甚至上千顆的 Spark node 或是 Hadoop node,這在 Andrew 所處的 Sales team 看來,這就是值得關注的潛在市場(Total Avaliable Market)與服務市場規模(Serviceable Available Market)
NVIDIA 希望讓所有資料科學的運算,小至獨立工作者,可使用 single workstation leverage rapid 進行開發;大至需要利用 Spark with GPU with rapids 處理大量資料的企業,都可以採用 NVIDIA 的解決方案。
另外資料科學中大家比較熟悉在 Python 生態系裡的:Pandas、Scikit-learn、NetworkX… 等原生跑在 sinlge CPU或是 multi-core 的套件,Rapids 提供這些套件的 GPU 版本。
NVIDIA 在開發 Rapids 的原則就是希望使用者不需要改動太多程式碼就可以利用 GPU 來進行加速。
之前利用 GPU 運算只能寫 CUDA code 來控制記憶體進行效能提升,但是 CUDA code 的學習曲線較陡,你要了解硬體、記憶體、整個 profiling…等,採用 Rapids 裡各式 library 的好處是,你可以在 High-level layer 透過 NVIDIA 或是 opensource 所維護的 API 進行效能提升。
比如你下一個 pandas.read csv 的指令,連 I/O 都能幫你加速,因為讀取資料需要經過 decoding、 parsing 過程,在資料量大的情況下,採用 GPU 的好處就非常明顯,更精確的說是可以獲得軟硬體整合優化的好處。
而剛剛所說的開發原則,可以讓 pandas.read csv 跟 CUDA data frame read csv, ** 兩者 API 相同,要提供的參數也相同,對開發者來說可以不用改 code 就可以直接利用到 GPU 運算效能**
NVIDIA 軟硬整合架構分享
Andrew 接著分享了 NVIDIA 從底層硬體到上層應用軟體的架構
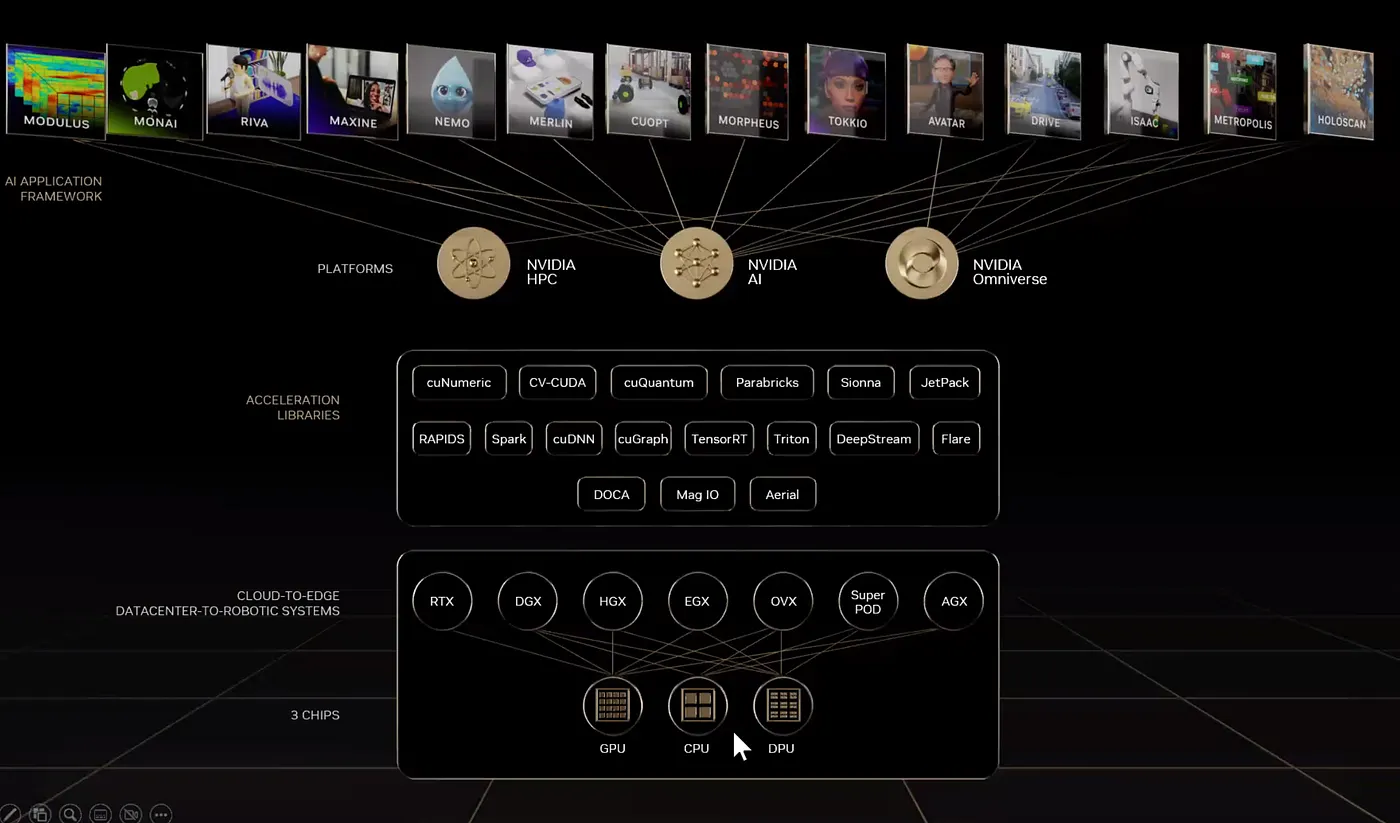
3 CHIPS
過去 NVIDIA 比較專注在 GPU,後來也開始關注 CPU,因而在去年有收購 ARM 的計畫。但因為各國監管單位的反對而無法交易,但 NVIDIA 還是持續在發展 ARM 這塊的 ROM(Read-only memory,唯讀記憶體)。
另外還有 DPU,這裡的 D 是 Data 的意思,可以想像在每個網卡都放一張晶片讓 networking 在處理時,有些功能可以讓網卡處理。原因是以前 single node 可以不用考慮太多 node 之間的溝通,可是現在很多模型,例如大型語言模型的訓練,就需要很多跨 node 應用之間的溝通。像在 spark 下有那麼多個 node 要一起做運算、要做shuffling 就包含:跨 node 之間的 aggregate、consolidation 的 operation 需要處理。
這些原本都是仰賴 CPU 進行溝通,包含告訴每個 node CPU,有交換資料的需求,資料需要放進各 noed 的 system memory…等,這些溝通就讓效能難以提升起來,所以 DPU 扮演的功能,就是希望 off-load 原本 CPU 在做的事情,讓 node 之間的 communication 或是 aggregate 在 DPU 就完成 。
NVIDIA 後續就是針對 GPU、CPU、DPU 這主要的 3 個硬體晶片會有持續有 roadmap 發布。
CLOUD-TO-EDGE, DATACENTER-TO-ROBOTIC SYSTEMS
在晶片之上的系統包含 RTX 做 rendering;DGX 做 deep learning;HGX 做 hyperskill,各種HPC(High Performance Computing,高效能運算);EGX 是 industrial edge;OVX 針對數位孿生開發,因為數位孿生的開發包含3D,rendering 跟深度學習運算的 configuration 會不太一樣;Super POD,當有 POD 這個字眼出現,就是它不再只是 single node 而是多個 node,多個 node 就會有 networking、switch、storage 需要處理;Jetson AGX,就是 ARM-base 的晶片。
這些所有的硬體大部分都是跟 OEM 的硬體廠商合作,像是 Dell、HP 或台灣技嘉、華碩、廣達…等等,研華、ADLINK 也有提供 Box Server 包含上述的這些系統。
ACCELERATION LIBRARIES
這層包含了各式各樣的軟體,圖上並不是所有 NIVIDA Library,大概只有十分之一甚至 1% 而已。而今天後續會談跟資料科學相關的:Rapids、Spark。(圖中左側)
PLATFORMS
再往上是 NVIDIA 主要的 3 個平台:HPC、AI、Omniverse(數位孿生相關)
AI APPLICATION FRAMEWORK
平台之上就是各領域特殊的模型
- MODULUS:用於增強神經網絡模型
- MONAI:用於處理醫學影像相關模型
- RIVA:用於語音對話相關主題
- MAXINE:用於提升視訊會議的體驗,像是眼神對焦,無論講者是否在看簡報,都可以將講者眼神對準鏡頭正中間,增加與會者互動感;降噪功能,可以將背景噪音濾除。
- NEMO:用於 NLP(自然語言處理)相關主題,包含語音辨識、文字轉語音等等。
- MERLIN:利用 GPU 加速推薦系統。
- CUOPT:用於提升最佳化演算法,譬如說 Tabu Search 或是各種的最佳化搜尋。
- MORPHEUS:用於網路安全領域。
- TOKKIO:與客戶服務相關。
- AVATAR:可以創造出許多虛擬角色。
- DRIVE:與自駕車領域相關。
- ISAAC:與機器人領域相關。
- METROPOLIS:跟智慧城市、工業檢測的應用有關。
- HOLOSCAN:用於處理各種 sensor(感測器)
從應用層面可以看出 NVIDIA 其實專注在很多領域,每個領域都會有專門的 BD(Business Development), GM(General Manager)協助客戶利用 domain-specific library 幫客戶創造價值。
從圖中也可以看出應用層會使用跨 PLATFORMS 的技術,舉例:AI plaform,很多應用都會跟 AI 有關,另外像HOLOSCAN是處理大規模感測器的,就會用到 HPC 與 Omniverse digital plaform。
NVIDIA 定義之資料科學領域 4 個適合加速的應用場景
Andrew 接著在分享 Rapid 加速 Spark 之前特別提醒:
當企業或是個人在思考整個流程加速時,需要 E2E 去找出整個流程中的效率瓶頸,再進行加速,比較能讓加速效益發揮出來。
在資料科學領域 NVIDIA 統整出 4 個加速情境:
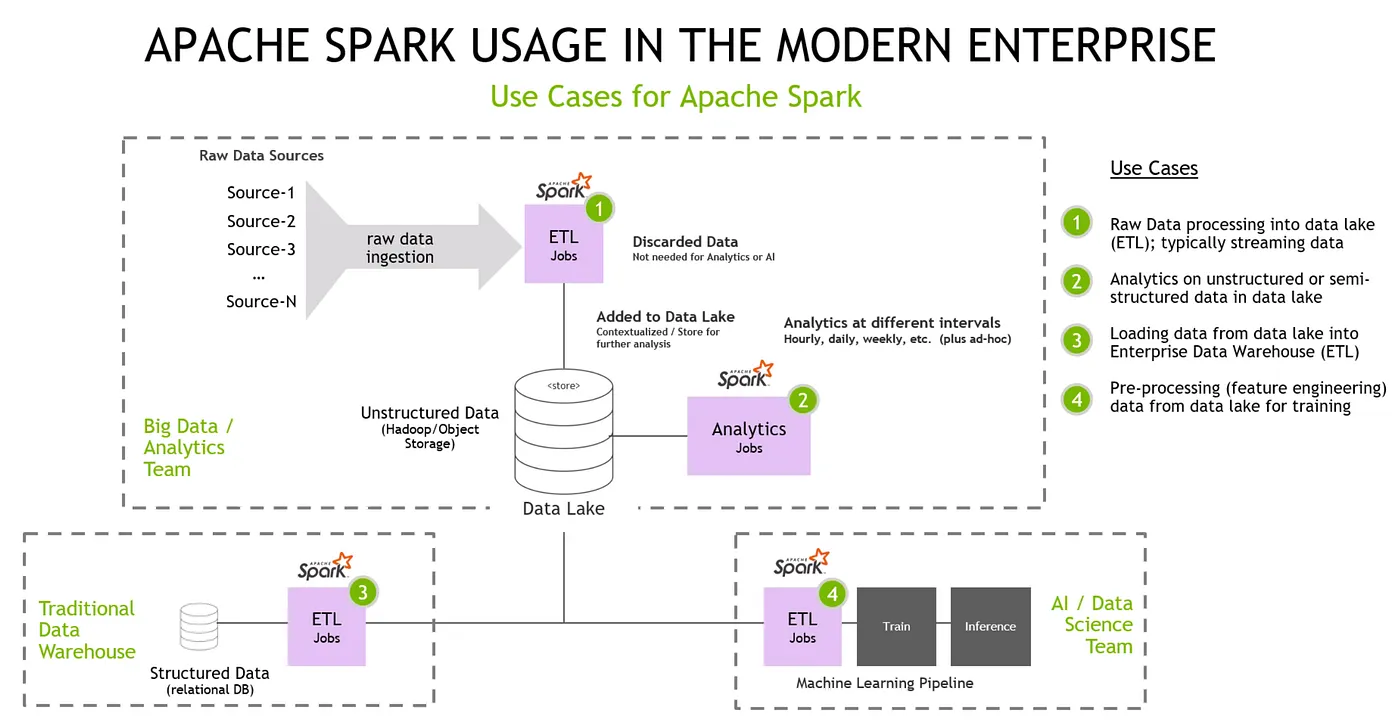
1. Raw data 處理
raw data 在這幾年越來越 ubiquitous,像是大家說的 IOT 或是各種的 data 越收越多。這在資料科學領域其實是個雞生蛋、但生雞的問題,過去大家會覺得自己沒有 big data 因此不能做 big data 分析,但不做 big data 那其實也不需要收集那麼多 big data 資料。
但以 Andrew 的角度看到 AI 近年的突破,其實都是 data-driven,從收集資料到獲得 data insight,然後做出各種預測與判斷,這樣的模型越來越常見,一開始是小小的模型,但漸漸企業會認知到自己需要利用各種 source data 放進模型做訓練,無論是感測器的資料、圖片、影像…等資料的處理也變成一個需要解決的重點。
這些資料收進來第一個遇到的問題就是 ETL(Extract, Transform, Load),一般企業收進來的資料,其實跟 Kaggle 上面看到的資料相差很遠,在 Kaggle 上的資料可能是漂亮的矩陣,column & row 的定義也都很清楚,但企業收進來的資料都非常亂,需要依照定義好的 schema 將資料存進 database 裡,而每天資料收取與存儲就是機器學習的一個瓶頸。
之前企業就是因為做不了即時大量資料處理,所以就退而求其次採用 batch(批次)的做法,也放棄 real-time(即時性),把前面收進來的資料做一些限縮,用統計的方法以 sampling(抽樣)的方式來做資料分析。
所以第一個應用場景就是:將結構化或是非結構化的資料依照 schema的資料存進 database 裡,舉例 NVIDIA 客戶:Walmart,就有很多資料需要即時處理,因此在 ETL 的過程中就有使用 Spark或 GPU 的需求。
2. 資料分析
當資料落地後,不只機器學習需要做資料處理,光是萃取各種指標放到 dashboard 讓決策者決定存貨要放多少?不同季節該如何推估存貨量?各種分析如果資料量一大,其實也會需要 Spark或 GPU 進行加速。
3. 傳統資料倉儲的資料存取
企業裡會因應不同的 use case 將資料依照應用需求階層式地將 raw data 經由 ETL 放到不同的 database ,這邊也會有許多 ETL 需要加速的需求。
4. 訓練資料前處理
企業裡的資料科學家或是機器學習工程師,通常會接收到老闆的任務,需要訓練出模型來做存貨預測、良率預測、預防維護預測…等等,那這些角色就需要到上述的 data lake 撈資料來進行訓練,當然這些資料不會像 Kaggle 上被整理得那麼好,所以在訓練前的資料前處理,也會有加速的需求。
在這 4 個場景其實過去通常是用從 Hadoop 或是 Spark 以 CPU 作為運算節點進行 scale out ,但 Andrew 分享他博士班畢業後到鴻海時,就發現 Spark ,相較於 Hadoop 比較專注在 batchwise(批次)分析的套件, ** Spark 利用 in memory 或用 lazy evaluation等等的技術,更能做到 interactive 分析,可以針對資料進行很多互動式的探索** ,進而發展到下一步,因而剛到鴻海的 Andrew 就積極推動建立 Spark 環境。

Spark 一開始還是在 CPU 上做加速,但 NVIDIA 看到了 CPU 透過 Moore’s law 提供的效能提升已經漸漸趕不上需要分析的資料量
無論是資料科學領域、或是 Andrew 過去生物醫學領域要做基因定序,這些領域所需處理的大量資料,會更需要 GPU 來進行各式運算。
其實 NVIDIA 建立 GPU platform 就是希望能補足這段差距,從 Spark CPU 版本跳到 GPU 版能把運算效能大幅提升起來,讓資料科學家或是機器學習工程師可以不需要因為基礎架構的限制去限縮要分析的資料量。
Rapids 加速資料處理流程
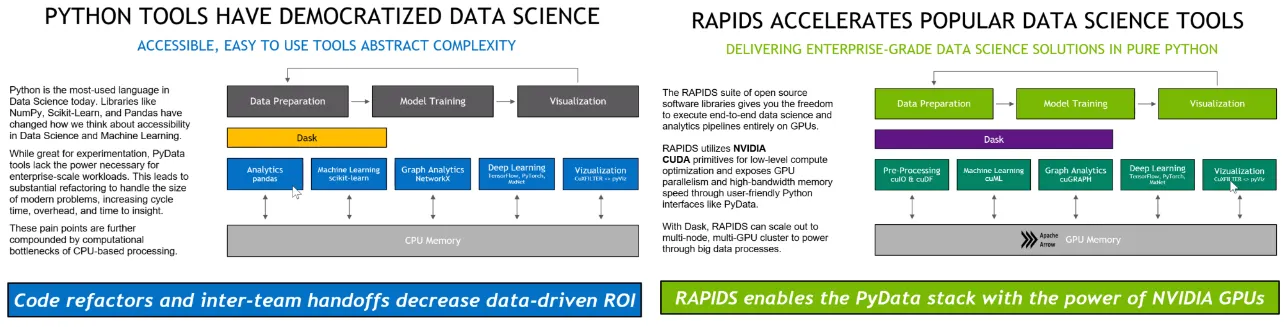
資料科學的流程,從 data preparation、model training、visualization,在原本 Python ecosystem 下大家應該對以下幾個套件名稱都很熟悉:Pandas 做 data frame 操作;Scikit-learn 做 machine learning;NetworkX 做 graph 分析;Tensorflow, Pytorch 做深度學習;pyViz 做 visualization。
換成 Rapids 的話,就是原本使用 CPU 記憶體的都換成 GPU,也就變成是 cu 開頭的,cu 代表 CUDA。所以從圖上可以看到CUDA可以加速I/O、data frame、machine learning、graph analysis、visualization。
這邊提一下 Dask,這也是 Python ecosystem 原生的套件,它跟 Spark有點類似,只是 Spark 還是 based 在 JAVA JVM,但是 Dask 是 Python原生的套件,你可以用讓你的 CPU 變成 multi-thread、multi-node。
其實 NVIDA 在發展 Spark後也把 Dask 的開發者也 hire 進來,希望利用他對 Dask 的 domain know-how 的理解,針對整個 ecosystem 來幫助 NVIDA 發展整個rapid ecosystem 的應用能更貼切 developer的需求。
另外一塊是:Apache Arrow,希望定義一個比較 enterprice 的 memory format 讓各個不同的操作的過程當中,不用花太多時間在做資料格式的 reformat。
因為以前最早就是用 data frame 加速,有一些公司用 visualization 加速,但當 dataframe 加速後要轉換成 visualization,還要把資料落地,在做 memory format 轉換過程有些是 cloum-baes 有些是 row-base,在這轉換的過程當中又花了很多時間。
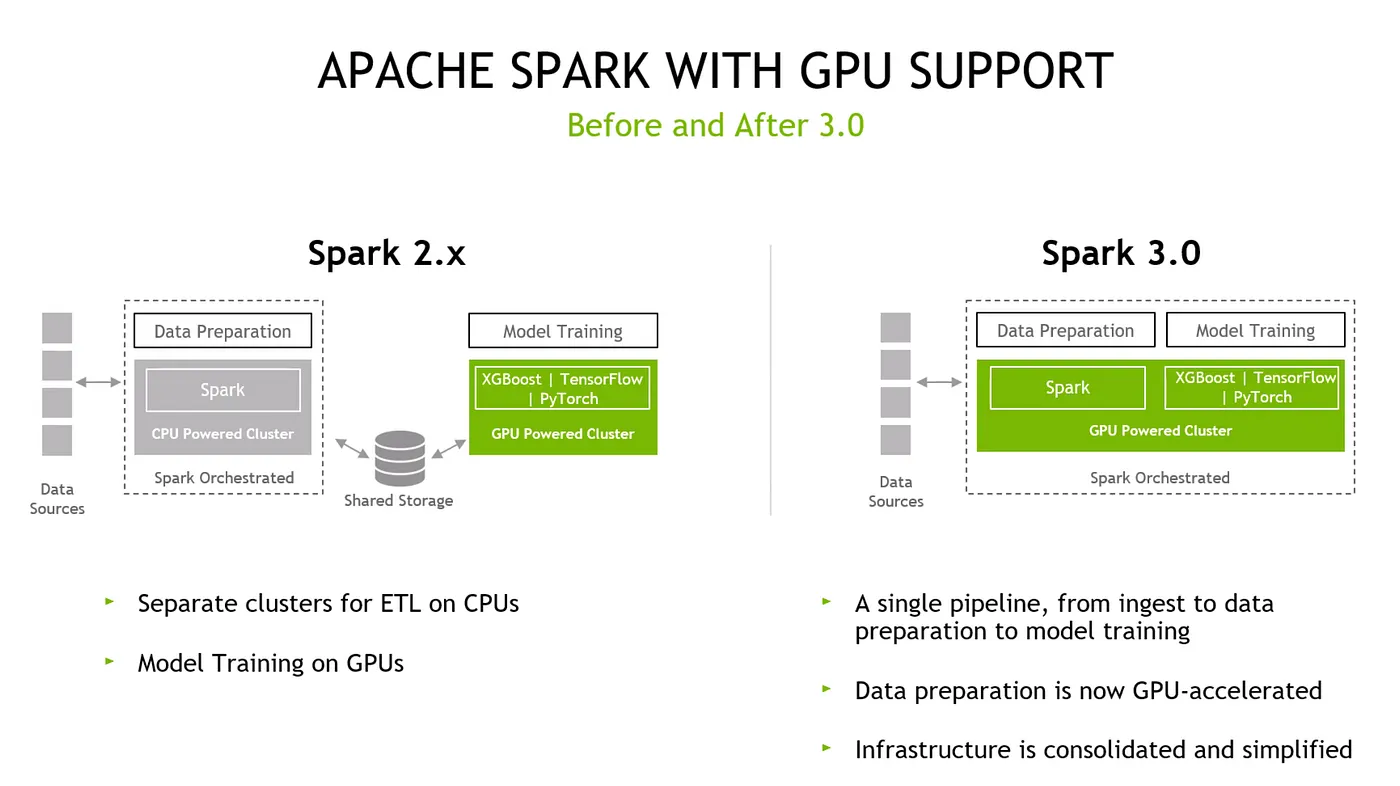
其實在 Spark 2.0 到 3.0 有個非常獨特的切入點是,過去在做 data science、spark、machine learning、deep leaning 的節點,在架構面其實是拆開的,目前大部分公司應該都這樣做,但拆開來會讓你 E2E 應用會被分開,甚至在企業內部是不同 team 在管理。
當企業在使用 Spark 2,0 訓練模型時就必須使用 shared storage 進行溝通,但透過 Spark 3.0 則是將 data science spark、deep learning spark 節點整合在 unify 的架構下,每個節點插一張 A100 或兩張 T4,讓每個節點都有獨立的 GPU 進行運作,並且將節點間的網路調整成 100G, 200G 的高速連線,利用 RDMA/RoCE 架構,就能讓節點間的 shuffling 更有效率。
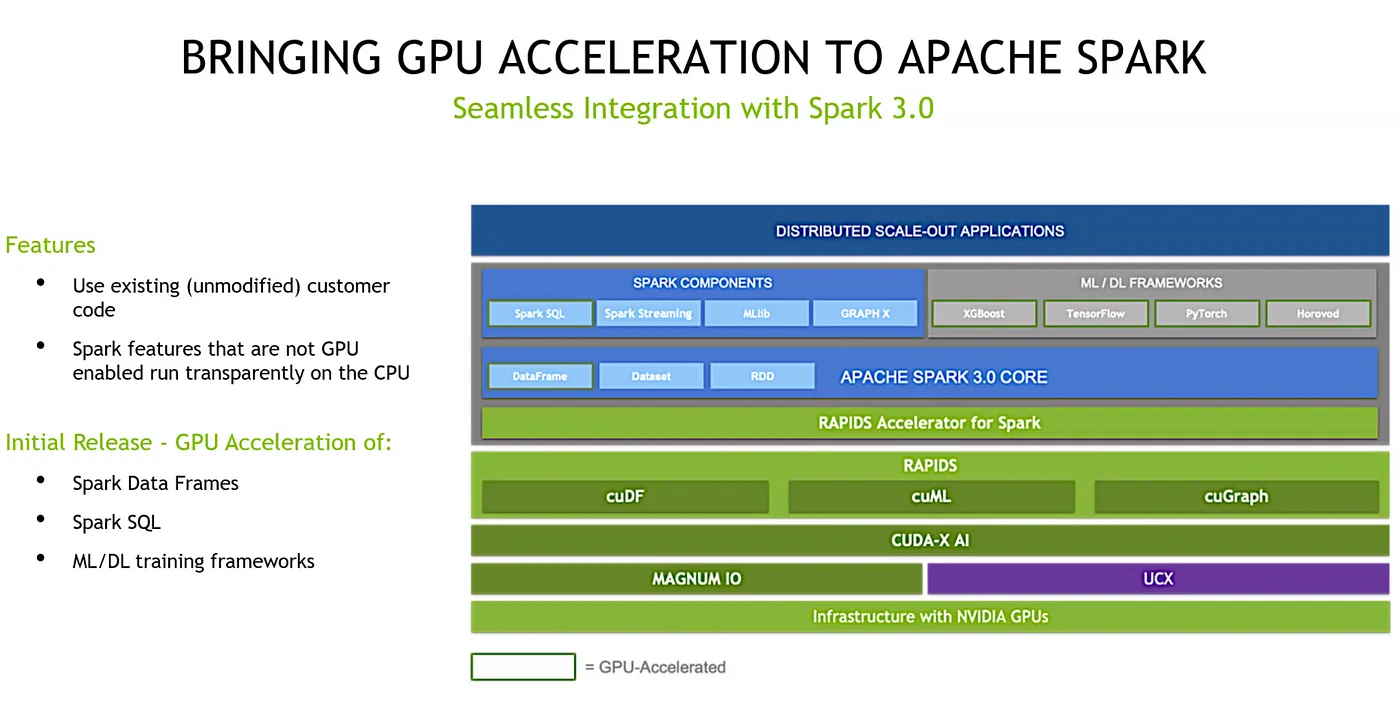
用上面這個架構圖說明: GPU 上面有 UCX 這個 library 協助 node 之間的溝通,上面會再利用 Rapids 的 cuDF, cuMK, cuGraph 進行處理。其實 Rapids 不只有這裡提到的套件,Rapids 2018 在德國舉辦 GTC 時發布,當時 NVIDIA 也招募了很多 Spark community 的人進來發展 Rapids,因此可以說 Rapids這個元件已經開發讓 Spark leverage 時可以很順暢。
當然還有很多要持續開發的套件,但目前是 Spark 3.0 後,你可以利用 Rapids 的這些 ingredients 來加速 SQL 或 data frame 的操作。
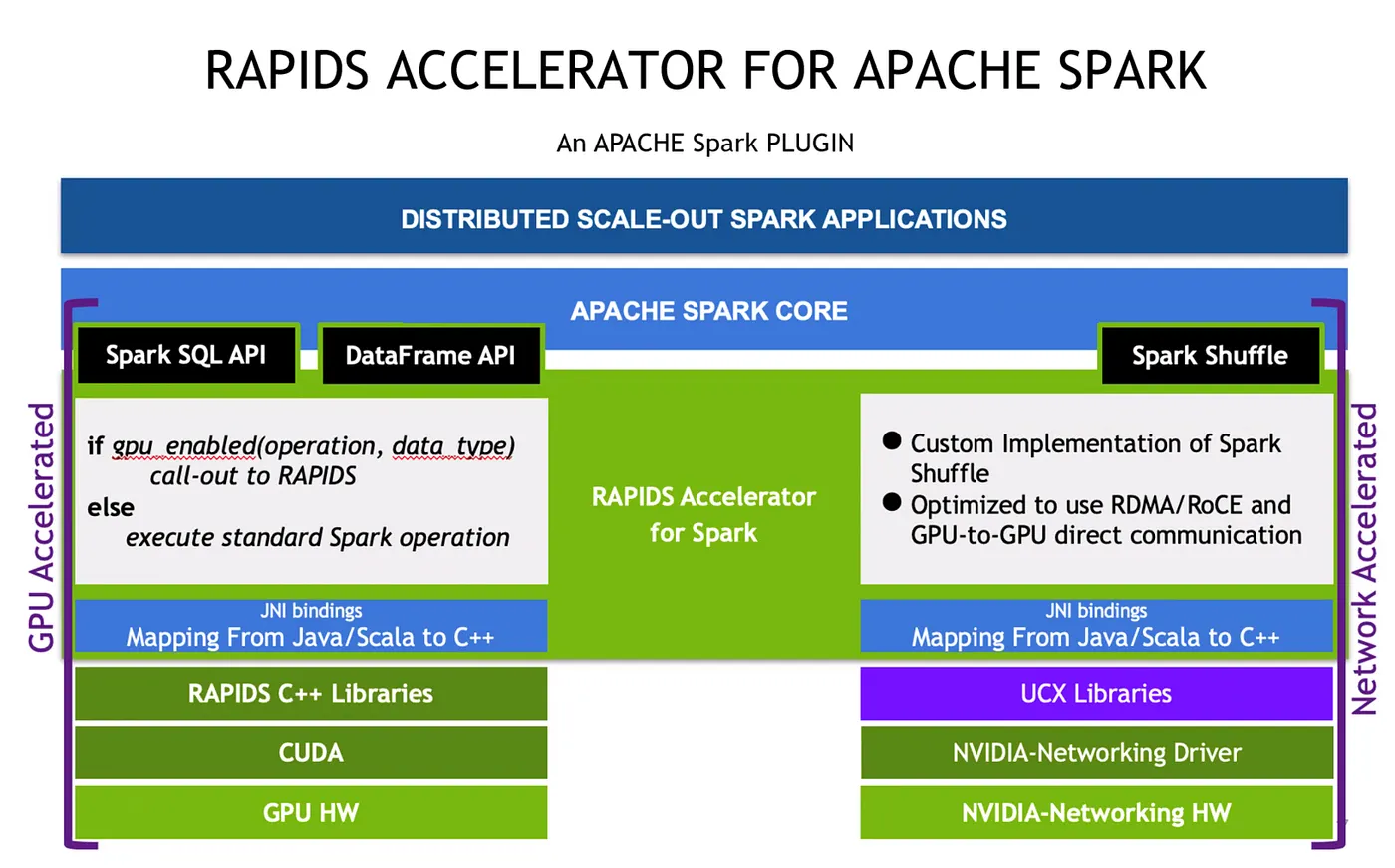
簡單總結一下:假設你要用 Spark 3.0 with GPU 版本,3.0 以上的版本透過configulation 會自動幫你判斷每個 application 有沒有 GPU support,如果沒有就會直接轉換到 CPU,所以你的 code 不用改,只要 configulation 改指到 GPU 就可以,也不會因為某些 application 不支援 GPU 就整個 crash。
這就是整個schedule 這塊所做的一些自動化設定,目的回到一開始說的開發原則,讓使用者不用改 code 只要 infra ready, software version ready(3.0),改完 config file,基本上要實現 GPU 加速 with Spark 就不會太困難。
另外一個是 Spark的 shuffle 都是 under the hood,可以透過 UCX 的 library,利用 RDMA/RoCE 讓 GPU 間、node 間溝通更有效率。
在實現 GPU 加速 with Spark 其實比較困難的是,當 Andrew 在跟客戶討論架構面的翻整,除了加速效益外,客戶還會考慮到成本。
比如說客戶要升級到 GPU 版本,整個 infra 上每個 node 都要插 GPU,從 IT 的角度就會是蠻大的工程,對企業來看還要考量這整個轉換過程中所花費的時間、開發者需要做的轉換、生產力的影響…等等,這個反而是在推行這個架構跟客戶溝通上比較困難的地方。
選擇適合的應用場景,實際獲取 Rapids 加速效益
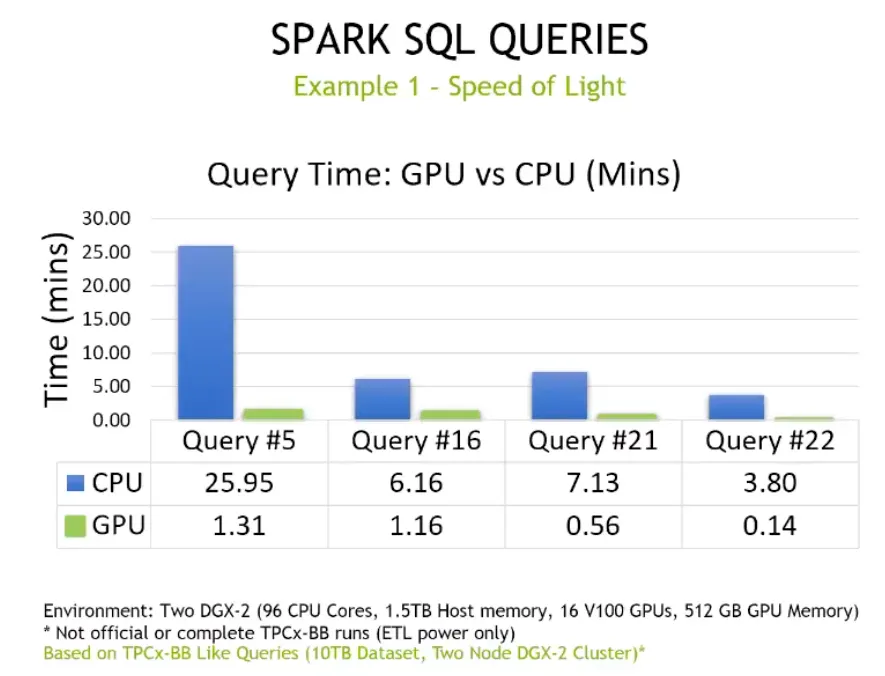
Andrew 最後跟大家分享幾個 benchmark,有個類似 MLOps 的 performce benchmark 資料叫 TPC x-BB,這個 Query 是用兩台 DGX 2 有 96 個 CPU cores,每一個 DGX 2 有 16 張,所以有 32 個 GPU 的條件來做 benchmark。
這個測試會涵蓋大概三四十種情境的 Query,有些比較簡單的 Query 效能提升就沒那麼顯著,可是比較複雜的 Query 效能提升就滿顯著。
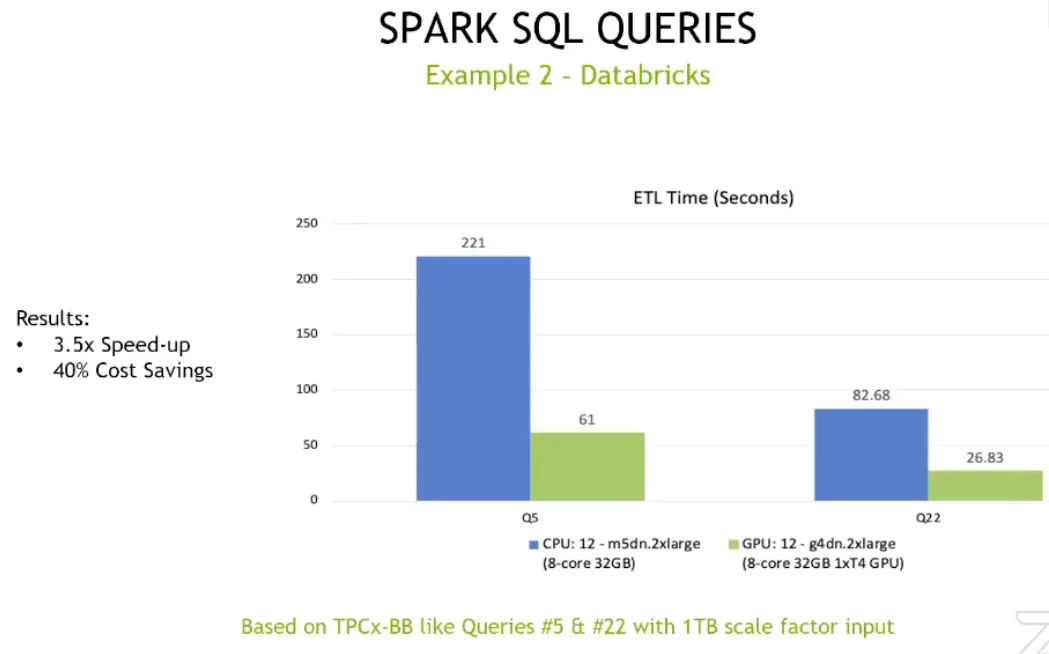
另外也有在 Databricks 上測試,Databricks 就是可以在雲上(Azure、GCP、AWS 應該都有)使用的 SaaS 服務,可以不用管底下的硬體直接用 Databricks 做 Spark 運算。
這也回應到上面講的,當一家企業已經有在使用 Databricks,這種公司就比較容易用 GPU 加速 Spark 的可能,因為沒有硬體轉換的成本。
總結來說,要發揮 GPU 加速的最大效益,除了選對題目:複雜的運算,另外因為 Spark 需要跨 node 間的溝通,所以 networking,甚至 SSD 的速度都很重要,那當然還有memnory 的這個限制,這些都會影響 GPU 所帶來的加速效益。
QA
Q 1: 2018 年的時候 Spark要支援 GPU 需要特別去抓學術界的修改版的 Spark 安裝,請問 Rapids 是直接安裝,就如同 open source 的版本嗎?還是可以在現有的 Spark 群集直接存取?
A1: NVIDIA GPU Rapids 支援 Spark 讓它可以用 GPU 功能要從 3.0 或是之後的版本才支援,那 3.0 就是 open source community 的 Spark版本。
其實我們很多實驗也都在 single workstation 上做,比如說有 8 張 GPU 然後我有兩個 CPU 每個 32核 做的實驗,你只要在一台機器上安裝 open source Spark 3.0 以上版本就可以使用。
另外一個就用 Databricks,這是一種滿熱門的 Spark SaaS Solution,這個是走在雲上的解決方案,Databricks 上有不同 Spark 版本,一樣只要 3.0 以上就有支援 GPU 的功能。
第三種就是 Cloudera(35:38),這個主要是客戶私有雲的服務,但使用 Cloudera(?)時要注意,因為Cloudera(?)有分 CDH版本與 CDP 版本,CDP 版本才支援 Spark 3.0 以上,CDH 只能用 3.0 版本以下,所以假設你是用Cloudera(?)的話,要先確定有沒有升級到 CDP 版本? CDP 版本只要用的是 Spark 3.0 就是可以應用 GPU 功能。
Q2: 哪些application在台灣的產業應用層面會比較廣,或者是比較成熟?
A2: 我剛開始加入 NVIDIA 時跟企業的第一次會議,很常被問的是:「AI可以做什麼?」3–5年過去了,現在大家比較不會問這個問題,而是開始去問「要怎麼優化?」
回到這個問題,在台灣主要是兩個產業,第一個是製造業,他們有很多瑕疵檢測的題目,這個題目6–7年前就開始了,當時的效益還不明顯,但到今天做這件事情的效益就非常明確像是人員節省,效率提升,確保 data consistance…等。
像前段時間台積電,從 5 奈米、3 奈米、一路要走到 1 奈米,它的製程微縮 defect 的判斷會越來越困難,因而更需要 GPU 讓瑕疵檢測的流程更加速。 而半導體產業裡的 AOI 的設備商也會從 sensor 不斷收到 wafer 或mask 的資料,因此這些設備商也提供這些瑕疵檢測的 AI module,這也是一個需要 GPU 加速的客群。
另外一個產業是:醫療產業,像是 personology, genomics的資料分析在台灣的醫學中心,事實上做的也非常多,這兩個領域算是比較願意先投資 GPU 加速的產業。
Q3: 目前在很多資料科學家在那麼多team跟project的情況下,怎麼利用剛剛的工具來提升效率?就是有沒有一些實用的場景?
A3:我想要用兩個層次回答這題。
第一個:因為我自己看到很明確的趨勢是平行運算越來越重要,NVIDIA 持續把high-level 工具設計好,就像剛剛分享的 Rapids,可以讓你在既有環境,像是 scikit-learn, pandas 下使用 GPU 加速。
但這樣還不夠,因為你只會用這個 high-level 工具,第二個可以再往進一步是,如果你要更了解 NVIDIA 的硬體與平行運算的基本的架構,你可以更好的找到流程裡的瓶頸,提出更好的解決方案。
因為上層用的軟體如果可以解決客戶問題最好,可是通常不是那麼簡單,客戶問題可能還有牽扯到 data I/O,或是後面的 decoding, encoding,NVIDIA 提供的 的library 非常多,也不是一個 library 就可以 cover 整個 E2E pipeline。
所以你要能利用 profiling 去看看瓶頸發生在哪裏?這個就得靠你對平行運算架構的理解,才能找到對的解決方案,無論你是要寫 CUDA code 或是找到剛剛提過的套件來針對個別問題優化,才能真正幫助你解決問題。
Q4: 資料科學家在NVIDIA裡面的日常工作?主要會是什麼樣的工作?
A4: 我屬的BU是 Solution Architect,因此比較偏 Pre-sales 的角色,所以很常在開會溝通。
我們會跟 BD 跟debt tech(1:05:00)一起去擬定一些策略怎麼把一個 deal 完成,比如我們會跟客戶有初步的 POC,我們就必須提出符合 POC scope 的 architect 提案,當中需要包含哪些軟硬體。
如果再更係一點的分享,其實我們滿常跟客戶家的data science team, machine learning team有一些私底下的對話,怎麼樣推出一個 POC 讓這件事情可以 benefit 到團隊跟公司,當然這個過程還需要 top-down 跟客戶家的老闆提。
就像剛剛分享,想利用 GPU 加速是會動到 infra 的,如果沒有 top-down,只靠data science team, machine learning team 推行很容易無疾而終,所以是否能讓客戶管理層與執行團隊都能買單 GPU 加速為企業帶來的價值,是我主要的工作內容。
筆記手:Lavina Lu
校稿:Andy Chang
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!