
全端資料科學的心路歷程
講者簡介

Vance 擁有 Management Science 與 Data Science 背景,在台灣零售公司擔任過 Data Scientist,目前任職於 ViewSonic,在 EdTech 領域中誤打誤撞,把各種 Data 職位都做過一輪的勸世男子,將與大家分享各 Data 職位的職能重點與如何在公司利用 Data 創造價值。
講者聯絡資訊:
版聚回顧及重點摘要
Background 背景介紹
講者目前任職於 ViewSonic 的子 BU:Presentation Group 擔任 Data Engineer。Presentation Group 負責 myViewBoard 相關的軟體事務,myViewBoard 是 ViewSonic 推出專注於教育的子品牌,著重於軟硬體結合的教育領域 EdTech。
講者簡報 p.3
ViewSonic Data Team 成立近 4 年左右,講者在 3 年前加入,身為團隊早期成員,工作職責隨著 Data Team 的需求不斷轉換,因此嘗試了不同 Data 職位,累積一些感想與大家分享。
講者從交大 Management Science 與 Data Science 取得學位後,進入到本土零售商擔任 Data Scientist 做 Machine Learning 相關專案後,於 2021 年加入 到 ViewSonic 。
講者第一年主要的工作內容就是衝刺 Data Dashboard 內容,並找到有足夠決定權的 Stakholders 引導他們開始使用 Dashboard;2021衝刺完後公司逐漸需要更深入的 Data Insight 來協助達成 KPI、獲得更多軟體營收,因此 2022 年講者主要回到 Data Scientist 本務上,研究比較多 Data Mining, Machine Learning Projects;到了 2023 年講者則是轉換職位到 Data Engineer 的角色,主要職責是讓整個公司的 Data Team 合作流程更加順暢。
Data Positions
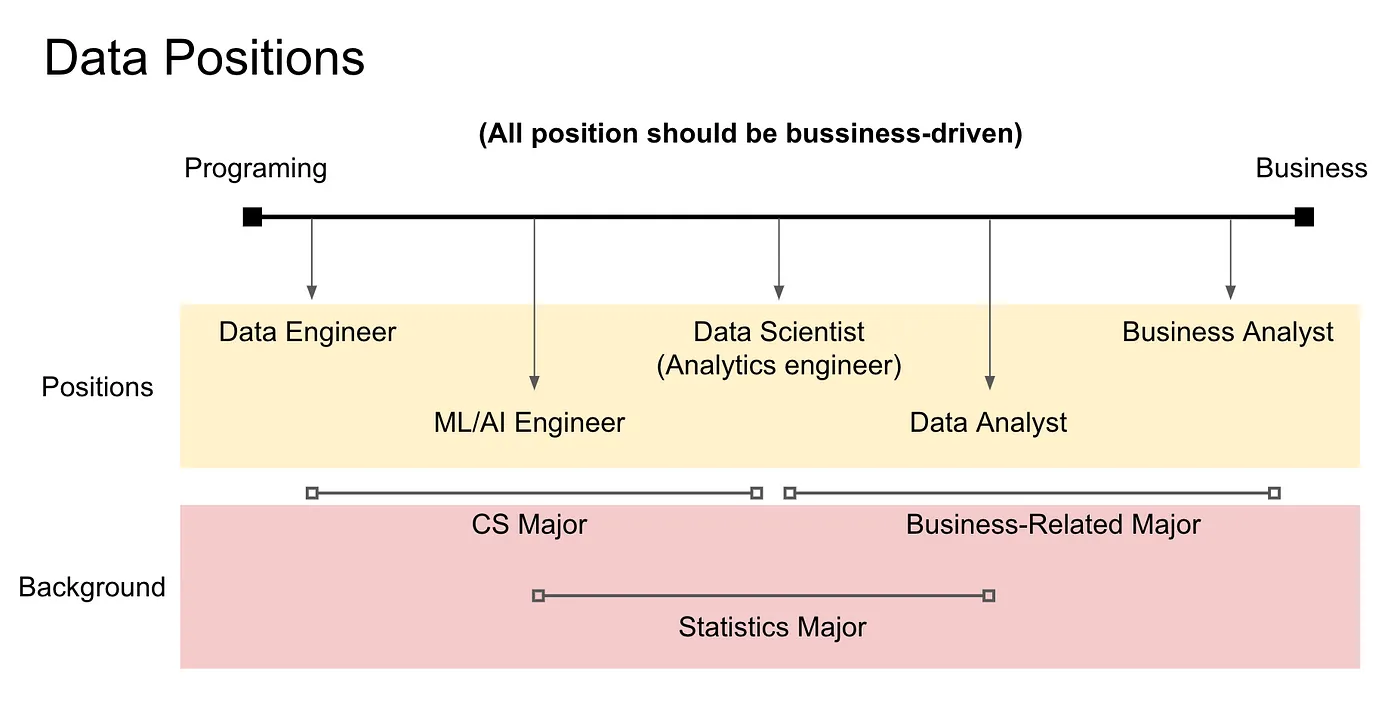
講者對台灣 Data 就業市場的觀察,認為每間公司對於各 Data 角色該做的事情落差滿大的,因此講者抓出兩個他認為 Data 領域兩個重要的 Metric:Programing 與 Business 來說明各 Data 職責重點。會以線性方式來呈現是因為這兩個 Metric 在時間投入上需要互相平衡,工作時間固定情況下,在一者投入越多,另一者的投入就會減少。
講者簡報 p.5
圖上左側最靠近 Programing 的角色是: Data Engineer,這個職位的職責滿明確的,只要負責穩定的讓資料落地到 Data Lake 或是 Data Warehouse,往 Business 靠近的第一個角色是:ML/AI Engineer,接著是相較中庸的 Data Scientist、Data Analyst,最靠近 Business 的則是 Business Analyst。
講者特別強調在 Data Scientist 下面有一個 Analytics Engineer 的角色,這個角色在分析資料時需要自己準備資料,而不是發需求給 Data Engineer,請 Engineer 協助開發 Pipeline,這個角色是近年在國外才興起的新職稱,台灣這個職稱的職位比較少,可能是未來一個新的趨勢。
投入 Data 領域的人大致分成三種背景: CS Major, Statistics Major, Business-Related Major
CS Major 的話應該大部分投入到 Data Engineer 角色,少部分會往 ML/AI Engineer 方向走,因為 ML/AI Engineer 會滿嚴格要求統計背景,未必每個 CS Major 的人都可以往這條路走。
Statistics Major 目前應該絕大多數是往 ML/AI Engineer 走,或是更往 Business 方向靠近,成為 Data Scientist。
Business-Related Major 的人絕大多數往 Data Analyst 定位,少部分的人會往 Data Scientist 方向走,以及有些人會往 Business Analyst。
Workflows & Data Value Chain
講者簡報 p.6
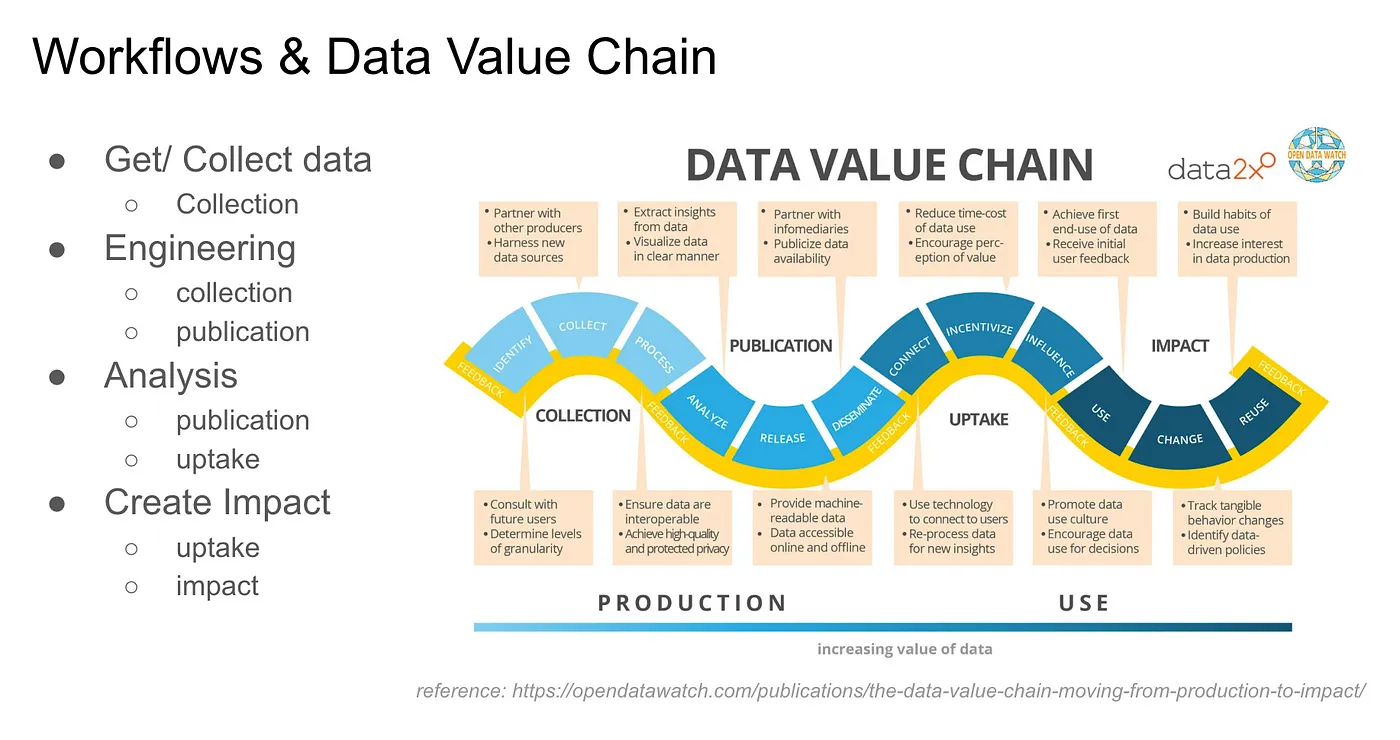
在講者分享的 Data Value Chain 框架裡,可以看出資料價值可以簡單被分成兩個區塊:Production & Use。Product 的形式很多元,可以是 Web Product, Dashboard, Strategy, Report…等;Use 就是實際使用 Product 產生影響。
從 Product 到 Use 中間可以拆分出 4 個階段:Collection, Publication, Uptake, Impact,對應到講者日常的 Workflow:Collect data, Engineering, Analysis, Create Impact。
講者強烈建議在 Data 領域工作的人可以整理自己目前的 Workflow 對應回 Data Value Chain,就可以了解自己距離真正「創造 Data 影響力」的終極目標還有多遠?還有哪些事情需要做?
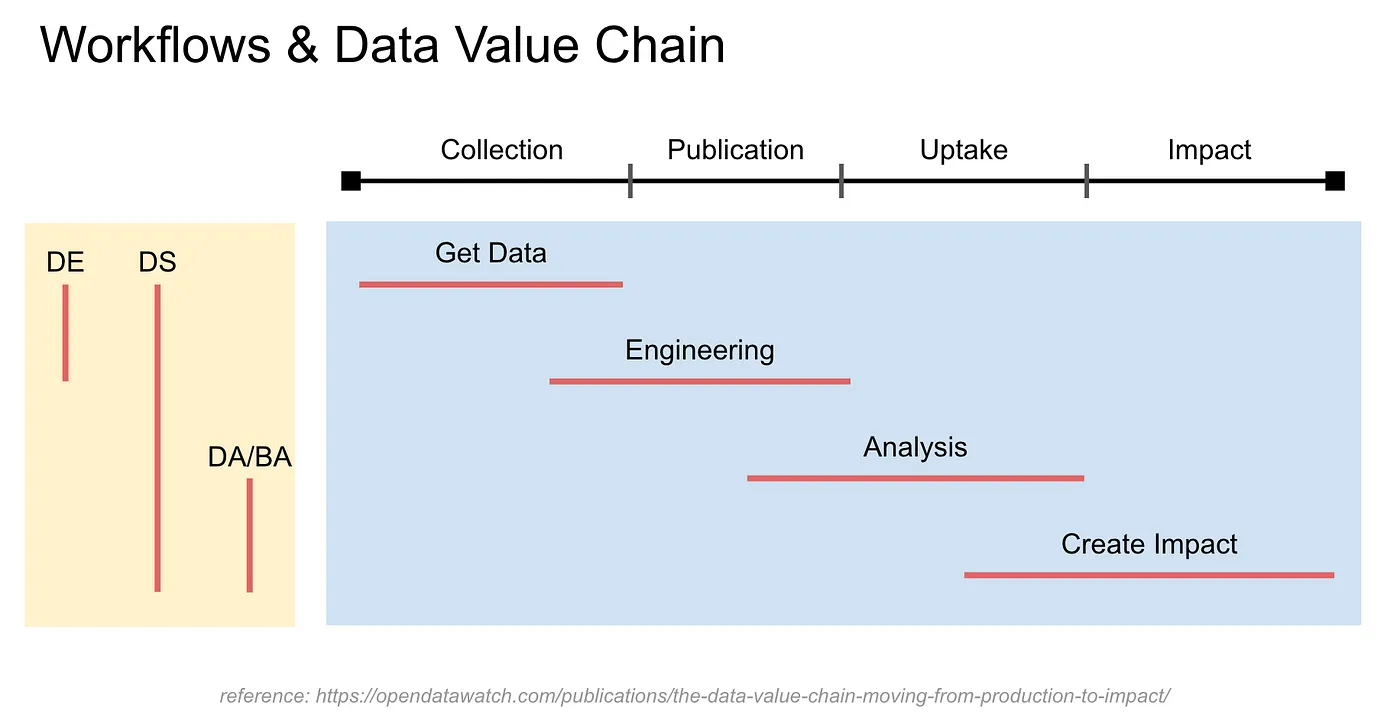
接下來講者用下圖右側來說明不同 Data 職位在 Data Value Chain 與 Workflow 上的職責範圍
講者簡報 p.7
- Data Engineer: 主要負責 Get Data 跟 Engineering,從收集數據到讓數據穩定落地到 Data Lake/Data Warehouse
- Data Scientist: 講者認為這個角色在新創團隊或是小團隊裡的定位是 Domain Owner,因此整個 Workflow 都要碰到一些。身為 Domain Owner 需要了解 Data 的產出背後經歷過哪些故事,這樣才能提出更深入的報告或是 Insight ,成為一個更好的 Storyteller
- Data Analyst/Business Analyst: 這兩個角色會比較專注於 Analysis 跟 Create Impact,只是 Business Analyst 相較 Data Analyst 會更偏重 Create Impact 這個階段
上圖左側則是對應 Data Value Chain 跟 Workflow
- Get Data 對應到 Collection
- Engineering 對應到 Collection & Publication
- Analysis 部分重疊到 Publication & Uptake
- Create Impact 對應到 Uptake & Impact
講者深入說明 WorkFlow 裡 4 個步驟的細節
- Get Data
主要在做 Event Tracking ,只是在不同產業會追蹤不同主體,例如說在 Martech 領域,可能 90% 以上的 Event 都是追蹤 User Behavior,如果在製造業,可能絕大多數的數據都是機台相關。
Event Tracking 會需要滿多跨 Team 協作,會因為不同產品、不同專案、對應到不同開發資源。合作對象會有 PM,前端工程師、後端工程師,在跟前後端工程師合作時,會接觸到不少跟 Software Skill 的事情,大致離不開兩項:API、Database。
— API:要注意資料流的流向、要明確定義什麼樣的資料流對於 Date Team 來說是正確的。
— Database :要知道 Database 的運作機制及資料結構。
最後很重要的是 Data Quality Assurance ,也就是 Data QA,在 Data 領域有在注意這件事情的人都知道這是個惡夢,因為在開發流程裡處於三不管地帶,但 Data QA 又很重要必須要做。
會說三不管地帶是因為,軟體工程師完成工作的定義:將符合 Data Team 開出的資料規格送到指定地點;PM 完成工作的定義:讓 Data Team 拿到所需要資料。但對 Data Team 來說,這兩者定義都不夠 Solid。
Data Team 需要的是資料除了要在指定的地方取得之外,還要以正確的方法被收集。
因此 Data Team 需要投資大量時間去確認:這條 Log 是以什麼樣的方式被收下來?這條 Log 在什麼情況下會收不下來?原因是什麼?當在開發前期做足 Data QA,Data Team 才可以很有信心的跟 Stakeholder 説目前所使用的資料是可信的,有做到 Data Reliability。
2. Engineering
Process/Pre-Process Data: 可以透過 ETL/ ELT 的方式或是 Streaming 方式取得資料。講者特別強調,在開發 Pipeline 時,除了要注意 Pipeline 的穩定性(Stability),還要注意 Consistency & Reliability,這兩個概念滿接近而且有先後關係。
— Data Consistency:Data Collection 條件固定的情況下,做完 Data Process 所得知之結果,無論邏輯或意義都不會變動。舉例來說:使用相同 Query,在今天取得 1/1 數據跟明天取得 1/1 數據,所得到的數字代表的意義是相同的。
— Data Reliability:概念上較廣泛,涵蓋 Consistency 跟 Stability,Reliability 的意義是,Data Team 與其他 Stakeholder 都可以全然信任 Data。要全然信任 Data 必須要經過上述所講,有做足 Data QA,能完全掌握這份 Data End-to-End 發生的事情,當 Data User 使用 Data 時遇到任何問題 etc. 為什麼資料有 NA (Null值),Data Team 才能提供較為合適的回應,建立公司對於 Data 使用上的信心。
Data Architecture: 對於普遍的公司來說每年或每天收集的 Data 量一定會穩定成長的,不外乎就是兩個原因,第一個原因:公司業務量成長;第二個原因:公司想要看的 Data 數量或 Data Metrics 變多,因而收集的 Data 量級會逐漸往上。
所以在建立 Data Pipeline 、建立 Data Process 邏輯、或是選定 Data Solution 時,都要考慮到擴充性問題,當然不用考慮到 10 年後,但可能要考慮到未來 1–2 年內,目前選用的解決方案是否有足夠彈性去處理逐漸增加的資料量級。
Version Control: 跟軟體版本控制一樣,在使用資料時也需要做相對應的版本控制
Data Governance: 這件事會跟公司治理、公司政策相關,講者在此提及是想強調 Data Access Control 實作端會落在 Engineering 階段,未來 Data Engineer 需要具備處理 Data Access Control 相關能力,有志往這個方向發展的人,可以投資時間研究一下。
Photo by Anna Auza on Unsplash
3. Analysis
EDA(Exploratory Data Analysis): 簡而言之就是在做大量的 Data Mining,通常產出的東西都是 Ad-hoc 形式,需要不斷 Try and Error,所以這是大家認為 Data 最好玩同時也最痛苦的 Process。因為 Try and Error 當下其實不確定最後是否有個 Useful Finding,所以這個過程蠻 Suffer,但當真的找到 Finding 的時候,又會覺得:哇!真的很棒!
Visualization: 大部分公司都是以 BI Tools 去做 Dashboard 提供給不同的 Stakeholders,以 Dashboard 為例,講者特別強調
Photo by Luke Chesser on Unsplash
— Keep it simple:每個 Dashboard 大概回答 1–2 個問題就好,因為當回答問題數往上時,一般 User 會發散,會沒辦法專注於 Dashboard 想回答的問題。
— Who:製作時要不斷確認 Dashboard 設定的 Target User 是誰?
— How:要用什麼有效的方式將特定 Insight 傳遞給 Target User?
— When:在什麼樣的時間點,傳遞 Insight 給 Target User?這點是最 Tricky 的,以軟體業來說通常 10 月開始會很忙,所以是否能把 Useful Insight 在 10月前先交付給 Target User,當 Target User 在制定策略時,就可以用上這個 Useful Insight,創造出 Data Impact,是可以思考與設計的。
Reusable: 在做分析的時候就思考,是否能重複使用這份分析?例如:今年初做了一份分析,明年是否能更改時間或是少量的 Metrics,這份分析就可以重複使用?因為分析部分相較繁雜,很容易會收到很多客製的東西,但 Data Team 同時開發的能量、時間沒那麼多,持續思考 Reusable,找到一勞永逸的作法,才能滿足眾多 Stakeholder 的需求。
Create Impact: 講者參加過許多 Data 聚會,發現不同公司、產業會有不同的做法來創造 Data Impact,因此結合自己團隊的作法分享給大家:
— Data Consultation:把 Data Team設定成公司裡的乙方,去承接公司各 Team 跟 Data 相關的需求,並提供各種不同 Data Service,舉例:回答各 Team 跟 Data 相關的問題,協助各 Team 收斂問題。
而 Consultation 背後的目標是為了達成 Promote Data Sense &Raise Data Culure
培養各 Team 都有具有 Data Sense 的人,讓他們知道如何正確且有效地閱讀 Data?如何從從數據中找到對應的 Insight 協助讓決策更 Solid?哪些決策可以尋求 Data Team 協助提升效率?
— Data Product Development:講者認為這是在 Create Impact 階段最重要的一件事情。因為當中小型 Data Team或是新創的 Data Team 發展到中後期,會遇到的問題是:Data Team 能做的題目面向、豐富度會逐漸收斂
因此就會需要 Data Product 讓整個 Data Team的產出維持穩定的狀態,讓團隊每月或每週在公司內部定期產生 Data Impact。
Photo by Jason Goodman on Unsplash
The Focus of Different Positions
說明完 Data Workflow 後,講者最後分享自己擔任不同 Data 職位時,分別專注哪些的重點
Data Analyst/ Business Analyst: 較專注於視覺化、報表相關的內容,藉由跨 Team 合作做到Promote Data Sense & Raise Data Culure, DA/BA 要去培養各 Team 具有 Data Sense 的種子,才能讓整個公司逐漸走向 Data Driven 的路。
更重要的是 DA/BA 要找到具有足夠決定權力的人來 Buy-In 團隊產出,尋找的方法就是透過不斷參加各種會議、觀察各 Team 裡每個人的表現、每個人的互動去找到這個關鍵人物。
這個關鍵人物不一定要是 C-Level,這個人物可能是個 Director、Senior Manager、或是 Regular Manager,不用去限縮這個人的職稱,只要有足夠決定權也具有一定程度的 Data 閱讀力、Data Sense, BA/DA 就可以把 Data 團隊的產出慢慢的賣給這個人 Create Impact。
Data Scientist :講者認為發展 Data Product 的部分責任會落在 Data Scientist 身上,當然這主要責任在 Team Lead 身上,但因為 Data Scientist 接觸到 Workflow 裡廣泛的階段,也會對應到更多 User,所以 Data Scientist 具有更宏觀的角度,去看 Data 如何在公司內產生 Impact、有機會從跟各 Team 的互動中觀察出 Data 產品化的機會,跟 Team Lead 討論。
Data Scientist 還要能預測未來性的需求,領先 User 1–2 步讓整個專案合作更加順利。
最後就是 Data Reliability,雖然 Reliability 這個主要職責是落在 Data Engineer 身上,但講者認為 Data Scientist 負責的 Workflow 相較廣,也會碰到更底層的資料集,所以 Data QA 也是 Scientist 可以負責幫忙的。
Photo by Mika Baumeister on Unsplash
Data Engineer: 工作職責相較上兩個職位單純,但 Data Engineer 要意識到自己是團隊最底層的建造者,在建立團隊基礎建設時,同時要觀察團隊成員間的合作情況是否順暢?是否有痛點?是否有 Gap? 是否有解決方案能解決?
Data Engineer 另一個主要職責是 Data Reliability,因為 Data Engineer 所花費的時間絕大多數都是在收集 Data 跟處理 Data,所以 Data QA 會是 Data Engineer 的工作重點。
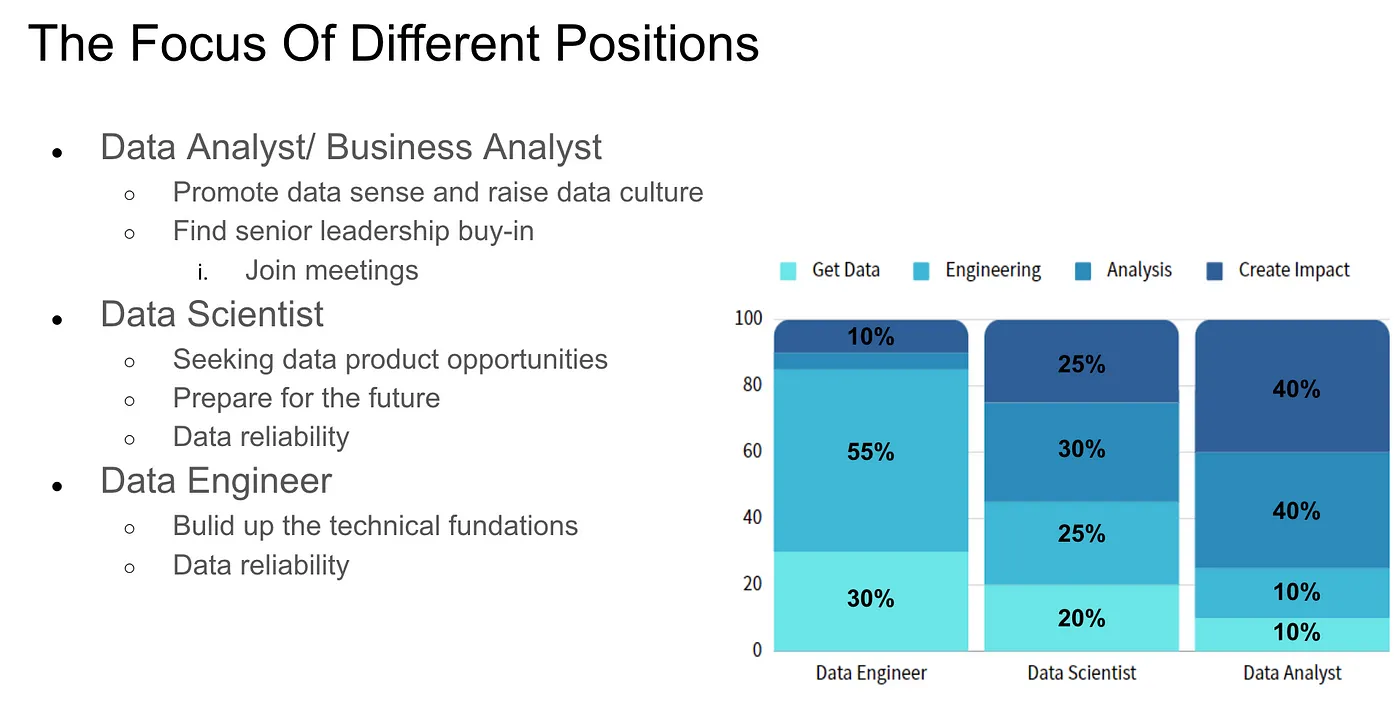
講者簡報 p.12
上圖右下角,講者粗略分享接觸過的 3 個職位,在各 Workflow 步驟中的工作佔比,想提醒的是 Data Engineer 有放 10% 的 Create Impact,這邊是 Data Engineer 在與前後端工程師合作時需要傳遞「如何正確解讀資料」的觀念給前後端工程師,而非要對一般資料使用者做溝通,主要是開發者之間的交流。
Data Scientist 接觸 Workflow 的各階段都很平均,除了 Analysis 之外,也要了解 Get Data & Engineering,這樣才會知道手上的資料是經過哪些處理才變成現在這樣,在取用、分析、解釋數據,才能夠對提出的結論有信心,能完善地回答 Stakeholder 的提問。
Takeaway
最後總結講者提醒兩個跟 Mindset 相關的事情
Be Business-Driven: 站在整個 Data Team 角度,不管是任何 Data 角色,都要 Be Business-Driven,只是因為不同角色能 Driven 的程度不同。
例如:Data Engineer 只要知道現在接到 Data Pipeline Requests 要 Support 怎麼樣的分析?這個分析之後是想要 Support 怎麼樣的決定?這個決定是由哪個 Team發起的?
但如果是 Data Analyst,就要再往下問:這個 Team發起的策略合理嗎?是否真的能符合公司目前的 Business Model… 等等之類的。
Ask for help, you aren’t expected to do things alone: 講者的觀察滿多 Data Team 成員都滿喜歡獨自完成事情,但這樣做會有一些問題,例如:開發時間過長,或者完全沒有考慮到使用者的需求…等等。
所以講者建議,如果遇到問題時,可以跟 Data Team 其他成員聊一下,或是遇到 Software Skill 問題,可以直接去找軟體工程師聊一下,詢問是否有什麼建議解法,或是遇到跟專案管理有關的事情,也可以直接去找 PM 討論,不要覺得自己被期待要一個人做完所有事情。
Photo by Desola Lanre-Ologun on Unsplash
最後針對 3 個講者擔任過的職位總結
Data Analyst: 分析要盡量簡單、視覺化圖表回答 1–2 個問題才能協助 User 聚焦,找到能 Buy-In 團隊產出的關鍵人物,不用在乎這個人物的職稱。
Data Scientist :要替團隊尋找發展 Data Product 的機會,讓團隊能穩定輸出 Data Impact。這個 Product 不一定要是 Website或是 APP,產品可以是A/B Testing、Recommendation 也算是一個產品,Product 形式非常多元。
身為 Data Scientist 盡量要心胸開闊,因為接觸到廣泛的 Workflow,可能會遇到 Software 相關問題、Project Manage 相關的問題,還有 Soft Skill 的問題,抱持開闊的心胸跟其他人討論,尋求協助,不需要自己完成所有事情。
Data Engineer: Data Reliability 是第一職責,再來是主動察覺團隊成員合作過程的痛點,或是 Workflow 上的痛點,可以主動提出解決方案協助團隊運作更加順暢有效率。
Q&A
Q1:Data Scientist 跟 AI Engineer 的差別在哪裡?
A1:兩者差別主要是「商業面」在工作中佔比不同。講者認為 AI Engineer 相較 Data Scientist 更投入在做研究,不太會花時間在商業面的事情;研究如何產生 Data Impact、如何符合公司目前的商業模式,則是 Data Scientist 比較常思考的。
Q2:若是非本科但 GPA 很好,無相關工作經驗,想申請 Data Scientist 名校,應該先加強什麼呢?或是要如何準備?
A2:講者認為可以回到 Data 領域的核心:在做任何事情都需要有很明確的目的。因此講者建議在申請、面試學校的當下,要很清楚告訴面試官「為什麼你想要申請這個學校、這個學位」你的動機要非常強烈,而且不只是用講的,還要配合行動,例如:你可以去參加 Kaggle 競賽,或是台灣其實有蠻多政府舉辦開放資料的黑客松,這些都是很好的佐證與累績經驗的方式,告訴告訴面試官你真的對 Data 領域是有興趣,而且你投入不少的時間在這件事情上面。
Photo by Ian Schneider on Unsplash
Q3:商管背景想轉職 BA 或是 DA,目前看到職缺都要有經驗,請問對於轉職、Junior 新手想跨領域有什麼建議?或是哪裡有可以累積相關經驗的職位?
A3:求職上需要累積作品,可能用工作之外的時間去累積,或是在工作上累積。
工作上累積相較簡單一些,講者建議可以自己觀察:「我目前的這份工作裡面有沒有什麼可以跟 Data Team 有合作到?或是跟 Data 扯上一點關係的?可能跟 Sales 有關、或是 Marketing Campaign 有關…之類的」,建議去找到這樣的機會,並積極爭取參與當中,或是成為主要負責人。
工作外累積,如同 Q2 的回覆,參加 Kaggle 競賽是個不錯的起始點,如果你今天目標是鎖定 BA/DA 兩個角色,建議可以多做一些視覺化的東西,想辦法把 Kaggle 的資料集轉化成 Tableau 或是 Power BI 的 Dashboard,或是你不需要這些 Data Tool,直接使用 Python 做一個 EDA(Exploratory Data Analysis)Process 都是可以嘗試的。
這些東西慢慢累積下來,都可以變成作品集,即便在沒經驗的情況求職,都可以是蠻好的 Reference。
Photo by Clay Banks on Unsplash
Q4:Version Control 的部分講者有推薦用什麼方式來管理 Data Set 的版本嗎?
A4:講者公司目前使用 AWS,用 S3 提供的 Version Control 功能。
Q5:Data Analyst 跟 Data Scientist 的合作契機跟分工方式為何?
A5:講者以自己 Team 運作來解釋:
Analyst 產生 Data Impact 的週期比較短,可能是每個月都需要對 Region 或 Stakeholder 產生 Impact。
Scientis 可能不用這麼頻繁,至少在講者團隊,這個角色被期待的是:產生一個新的 Metric 給團隊使用、或是產生新的 KPI 給 C-level 使用、或者產生更好的 Story Line 可以讓團隊產生 Impact,比較像是提供素材給 Analyst 的人。
Q6:最近有看到一些藥廠開出 Data Scientist 的職缺,但是工作內容跟製藥或者生物數據分析相關,請問這種職缺和傳統認知的 Data Scientist 是相同的嗎?
A6:講者依照聽眾提供的 JD,認為比較介於在 Data Scientist 跟 AI Engineer 中間。
因為 JD 混雜了蠻大部分統計背景相關的東西,所以講者認為演算法相關的研究,或是運用統計理論進行相關研究,會是這工作占比蠻大一部分的。
一般的 Data Scientist 比較是 Overall 的位置,接觸到商業端多一點。
Photo by Towfiqu barbhuiya on Unsplash
Q7:若要分析一份資料,但對產業或是資料欄位不了解的話,通常會在分析上做什麼特別的事情呢?舉例拿一份 Kaggle 資料來做分析,但沒有一個目標去做分析的話,會需要做什麼基本或進階的內容呢?
A7:講者建議要自己同時身兼多職,扮演自己給自己 Request 的角色,可以問自己:這份資料我想要看到什麼?自己設定很多題目,去試誤,了解哪個題目可行,然後慢慢收斂分析。
Q8:如果目前做的內容都是以 Data Analysis 為主,如何往 Data Engineer 學習或發展呢?提問者最終目標想做 Full-stack 但是專注於 Analytic Engineering 的部份。
A8:是否能讓你有環境去學習發展,滿取決於各組織分工情況。講者的組織分工情況 Analyst, Scientist, Engineer 在同個 Team裡面,所以彼此工作內容其實會稍微重疊。
提問者如果可以碰觸到一些 Engineering 相關的事情,可以嘗試作一些簡單的Pipleline 或是簡單的 Data Process 邏輯或流程,先從簡單版本開始做。
但如果你今天沒辦法碰觸到 Data Engineering 的 Workflow,你就只能針對 Data Warehouse 或是 BI Tools 嘗試優化作法。
Q9:Data Product 到底是什麼,能夠舉例嗎?
A9:Data Product 目前最常見的就是 Dashboard,不管是透過 Power BI、Tableau 或是其他Open Source 的 BI Tool 去建造 Dashboard 給使用者去看。
可是這樣其實還不夠,這也是為什麼有些團隊會專門成立 Data Scientist Team, 專門去負責 Recommendation 或設計 A/B Testing。這邊說的 A/B Testing 並不是一年嘗試一次,是常態性每個月或是每個週期都會做的東西,以這樣的定義來說,這個 A/B Testing 就是一個 Product。
只要是週期性持續優化整個公司 Output 的事,都可以是 Data Prodcut。
Q10:怎麼管理一間公司不同專案的 Data Analyst, Data Scientist, Data Engineer 的績效考核?
A10:講者認為需要回頭看團隊成立的時候對這 3 個職位有沒有設定需要產生什麼樣的 Output?如果一開始沒有設定這件事情,其實是很難進行後續績效考核。
例如你可能會期待 Analyst 需要在這 1 年內找到 5 個以上的 Stakeholder(Stakeholder 要分別代表不同的 Team或是不同的Function),這樣的設定才能進行後續績效衡量。
Q11:請問要如何衡量資料產生的 Impact?
A11:講者建議可回到 Data Value Chain,整理一下 User 目前處在 Flow 的哪個階段?是不是真的有使用 Data Team 提供的 Data 來做任何的決定?還是 User 只是看 Dashboard而已?這就是不同的 Impact level。
Q12:Data Analyst, Data Scientist, Data Engineer 這三個角色如何定義工作範圍的規則?
A12:可以回到上述「The Focus Of Different Positions」章節。
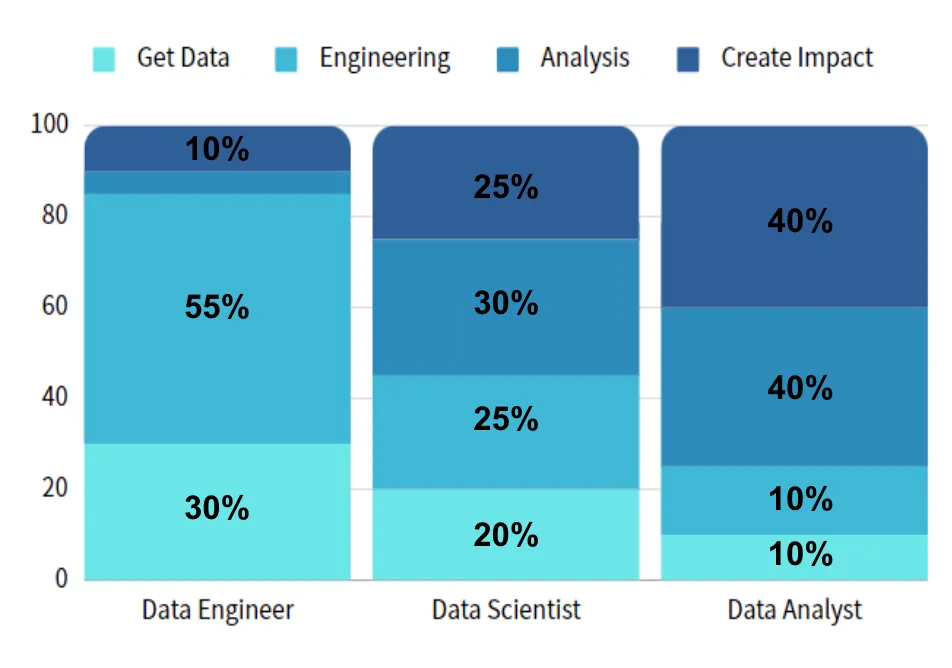
在講者的定義上 Analyst 跟 Engineer 在 Workflow 裡是毫無重複的,在職責上這兩者是完全互補,加在一起就是100%,分開來就分別是 50%。
Scientist 的部分的話就還蠻取決於團隊的定位,至少在我們團隊定位上來說是 Overall 的事情都要做的,只是在 Workflow 每個階段投資的時間不大一樣。
以講者自身經歷為例,身為 Scientist 時花比較多時間在做 Analysis, Engineering, Create Impct,在 Get Data 投入的時間就比較少。所以 Scientist 的工作範圍比較取決於在團隊中的定位。
講者認為 Scientist 需要隨時調整自己的定位,因為所有的事情都要做,例如最近 Engineer 的 Bandwidth 比較緊的時候,可能就投入多一點時間去Engineer 這塊,如果是 Create Impact 這邊資源比較緊的話,就是投入多一點時間到 Create Impact這邊。
Q12: 想問講者 ViewSonic 團隊是用哪些工具來建立 Data Pipeline的呢?
A12:主要就是 Airflow 還有一些 AWS Solution。
Q13:想了解講者從 Data Scientist 轉換到 Data Engineer 的契機是什麼?
A13:講者是團隊早期成員,會隨著團隊需求不斷的調整自己的定位。以今年來說,目前 Data Engineer 這邊開發能量比較比較不足,因此講者就轉做 Data Engineer。
筆記手:盧姵吟 Lavina Lu
校稿:蔡宗佑 Vance Tsai、張晏禔 Andy Chang
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!