
國際 AI Hackathon 入選決賽經驗分享
講者簡介

Jason 目前在昕力資訊(TPIsoftware)擔任資料協理(Director of Data)。昕力資訊主要提供金融保險業、電信業、製造業等領域相關解決方案與系統建置服務,特別專精於數位金融解決方案,數位銀行、行動支付、行動壽險業務、電子保單、網路銀行等系統,同時掌握跨平台行動App開發以及Big Data資料應用趨勢,研發與推廣相關自有軟體以及自有AI品牌。
原直播連結:點此觀看
Lablab.ai Hackathon 介紹
Lablab.ai 每週都會選定一個主題、一個技術舉辦黑客松(Hackathon),講者參與的是 Open AI 的主題,平台上還有 Stable Diffusion、Cohere、Whisper、LangChain…等科技主題,任何人都可以自行挑選主題參加。講者當時參加的是 Report Cruncher 主題,共有 7,315 個參加者、506 個團隊,最終有提出 prototype 的有 88 個團隊,講者屬團隊最後被選入決選前 7 名,從 7 名中會再挑選前三名獲得獎金,今天講者會跟大家分享:如何在世界好手雲集的 AI 領域參與黑客松,並脫穎而出進入決選的寶貴經驗。
關鍵第一步:如何選題
就像小孩在玩樂高一樣,你可以打造飛機、打造船,就像擁有技術的人能針對問題提出千百種解法,但最重要的第一步是你想要解決什麼問題?金融領域的問題?還是聽障、視障朋友可能會遇到的問題?
在黑客松裡好的選題,要確保在團隊能力下、在有限時間裡(舉例:7天)找到解決方案、產生一定的影響、並且獲得評審的青睞。
當時講者除了Report Cruncher 主題,其實還有在考慮另一個電商領域的問題,並使用 AI 辨識去分辨商品,但這個題目需要的資料集更多、開發所需的時間更多,並無法在短時間內達成有影響力的成果,因此講者團隊當時並未選擇這個題目。
Photo by Priscilla Du Preez on Unsplash
上述提到的團隊能力,就很講求團隊成員的多元性,像是要有熟悉商業知識的成員、有技術能力的成員(熟悉 Python, Java)、有資深資淺的成員、有懂 DevOps 的成員,這樣的團隊才能在短時間內推出完整的解決方案。
至於專案名稱,講者團隊也運用到最近很熱門的 Chatgpt,先丟 100–200 字的專案描述,然後請 Chatgpt 濃縮成 2–3 個字,並且要避免已經出現在市場上的名稱,或是已經被註冊的商標,在得到 Chatgpt 提供的結果清單後,團隊最後投票表決才決定專題名稱為:Report Cruncher。
定義問題與解決方案
下圖是一個複雜的財報,而 Chatgpt 原始的技術特性並不擅長處理這種複雜的數字,尤其在對數字精准度很要求的金融領域,Chatgpt 的回答如果不夠精確,可能會影響到公司的股價,影響到公司幾百億、幾千億的市值,這個就是講者團隊想用技術解決的問題。
講者團隊針對的使用者是:一般的大眾投資者,這些投資者缺乏資源、時間,也缺少相關財經領域的知識,因此講者團隊希望提供一個技術工具能協助大眾投資者快速的統整幾百頁充滿數字與文字的財報。
講者團隊的解決方案是:提供一個 UI 介面讓使用者能上傳 pdf 檔案,其實網路上直接搜尋 alphabet financial statement 就可以得到這些公開的財報,上傳後我們會提供一個類似 Chatgpt 的對話視窗,使用者就可以針對財報問一些相關問題,像是:今年的營收?公司盈餘?我們的技術就是可以針對上傳的財報給出使用者精確的答案。
組織團隊成員
題目定下來後下一步就是:招募團隊成員。招募成員時要能很清楚的說明專案背景,說明要解決的問題、表達出專案的意義與影響力,才能引起其他人的興趣。
而在組成團隊時,除了志同道合之外,講者也很講求團隊組成的多元性,講者本身是技術背景出身,因此在招募團隊時就會特別找具有商管背景的人選,最後加入的團隊成員裡,有一個是營運背景、另一個是做行銷相關的。
團隊多元性包含成員來自不同國家,生活背景不同的人看到的問題面向不同,像是印度人會覺得團隊的解決方案可以幫助有殘疾的使用者,協助他們在財經上進行決策,這可能是身在台灣的講者不會想到的服務對象。

因此找不同國家的人一起加入其實可以激盪出不同的想法,擴大解決方案能服務的群體與規模,但在考慮跨國團隊時要注意跨時區的問題。講者當初有想找來自美國或歐洲的成員,但因為時區的問題,最後還是找亞洲時區相差不大的成員一起合作。
講者團隊在開賽前三週將成員敲定,組成了跨六個國家五個不同時區的六人團隊,並使用工具:time and the days,快速篩選出跨時區的成員能同時上線參與專案的時間點,講者團隊使用的是 Google meet 進行線上會議。
選題在黑客松競賽裡面非常關鍵,最好是找大家都有興趣的,並且在開賽前確定下來,在開賽當天就能開始動工,把握有限的時間。
講者團隊在開賽前就先開過幾次會議將專案選題縮小至兩個選項,並且在開賽當天將題目確定下來,有效率地進入打造原型的環節。
打造原型(Prototype)與協作工具介紹

講者分享 2021 較熱門的程式語言是 Javascript, Python,因此講者團隊的 prototype 就是用 Javascript 為前端 Python 為後端的方式完成。團隊裡的德國成員懂 DevOps 流程,前後端的 template 各花一天就完成,有他的協助讓團隊前後端串接可以更順暢。
以下是依照不同需求場景,講者團隊所使用的協作工具,供大家參考:
- Shared Drive: Google Drive, Google Doc, Google Slides
- Python Notebook: Google Colab
- Code sharing: Github
- Team Whiteboard: Miro
- Presentation UI mockup: Figma
- Team Chat: Discord(or whatever suitable for everyone)
- Team Meeting: Google Meet
講者特別分享 Team Whiteboard: Miro 的使用方式:使用白板可以快速將專案依照順序分成四大面向:Business plan, Clickable prototype(Figma), Logic implementation(backend), Delverables ,並標記負責人與官方溝通的 Discord 群組連結。
講者團隊可以很快速地從 Miro 上看出專案是否還有欠缺的項目,快速依照團隊成員專長補位,像是有一個成員過去曾經做過 pdf 萃取的專案,就可以沿用之前的程式碼加速 Logic implementation(backend) 的過程。
Lablab.ai Hackathon 除了技術之外,更需要說明解決方案的市場價值,像是變現方法、市場需求、競爭者分析、價值主張、目標客戶…等,這時候團隊裡有懂營運的成員就很重要。
Miro 頁面截圖
從 Figma 上可以更視覺化地呈現最後的服務會怎麼提供給使用者,主要兩個頁面:

上傳 pdf 介面
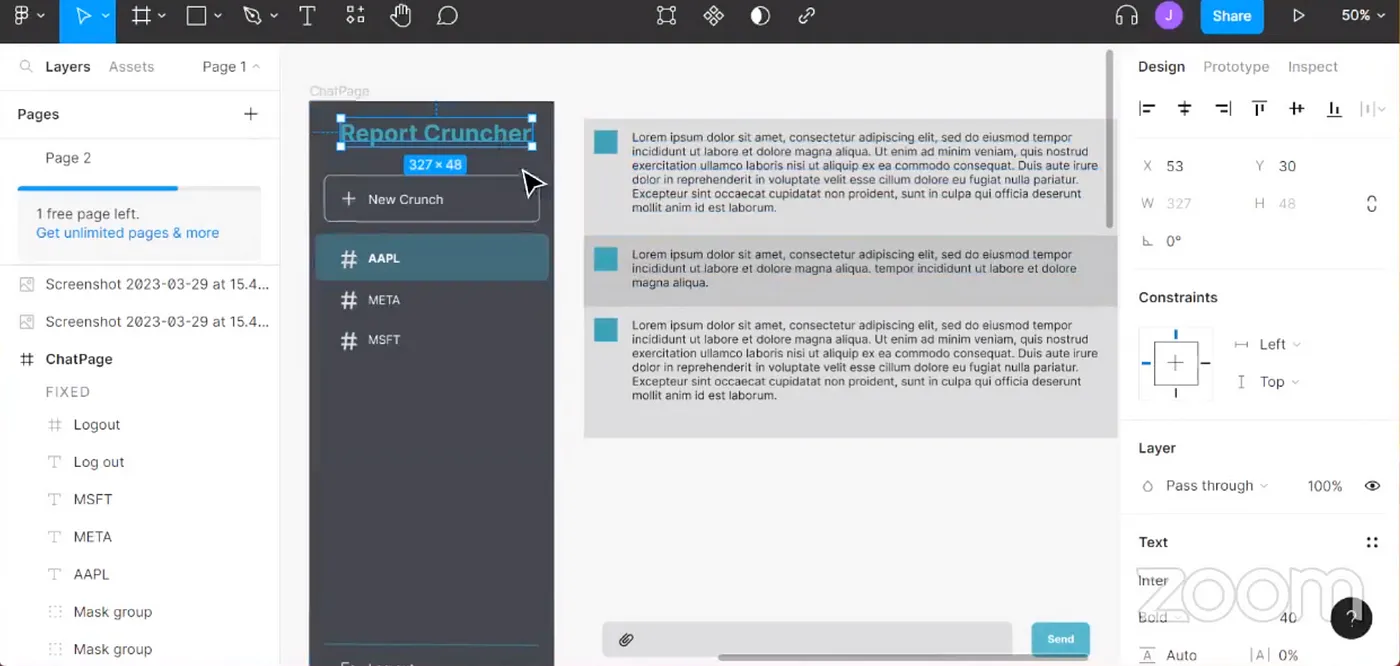
問答介面
Figma 頁面可用於比對最後 protoype 產出是否符合團隊成員的期待,細節到文字大小都可以做校對。
另外一個視覺化工具 Canva 也是講者會採用的工具,可以快速使用模板產出所需的視覺化內容,加速專案的溝通與執行。
在找訓練資料方面,建議大家可以從 google resource data 上面找相關的資料集進行訓練,講者團隊很幸運的找到 2022 年被上傳的論文有提到相關的資料集:Final financial summarization dataset,可以做使用。
前後端使用的模板,建議是用大家都在使用的模板,像是:streamlit 就是可以處理完前後端的 python library。以下是前後端比較主流在使用的 library,講者團隊在前端使用:React,後端使用: Python-flask。
- Front-end: React , Vue
- Back-end: NodeJS, Python-flask , Python-Django
使用主流 library 的好處在於如果遇到問題,比較好找到答案,或是一些現成的 library tool 可以使用。
團隊合作
在黑客松的比賽中,講者分享的團隊裡需要具備的幾個特質
- Creativity 創意:在發想解決方案時,團隊成員能不能很有創意地去發想解法,並且能真正解決到痛點。
- Technology 技術:有創意之後也要有技術力去實踐想法。
- Business 商業:最後就是問題與解法是否能在商業上產生價值,只有很酷炫的技術但卻沒有解決商業痛點,就會很可惜。
講者將上述三的特質加上 Leadership 畫出雷達圖來分析自己的強項,而團隊的組成就是要盡量把每個人的雷達圖疊起來,形成一個圓,那就會是一個比較好的團隊。
技術採用與雲端部署
在解決方案的技術層面,以下為講者團隊使用的技術與成本(費用與時間)

講者更細節的分享了模型採用的背後邏輯,可以看出 「訓練成本」 是選擇訓練模型不可忽略的因素:在 model 訓練時,講者團隊使用的是 ADA model,在註冊 Open AI 時會有 18 美金的額度可以使用,所以一開始講者團隊先使用這個模型,後來講者團隊想要用更複雜的 Davinci model,但會超出 120 美金的預算,所以最後是使用 Curie 模型,持續優化解決方案背後的演算法。
在雲端部署上,在考量穩定性與 github 串接的順暢度,講者還是推薦使用市場主流的三大公有雲:AWS, GCP, Microsoft Azure。
像是市場主流的 Heroku,講者團隊也有嘗試使用,但在運算過程並沒有那麼滿足需求,另外一個很有名的 HuggingFace,可以用來存 AI model,但缺少了操作介面,比較適合單純訓練 machine learning model 使用,在雲端部署上還是三大公有雲提供的解決方案比較符合需求。
獲獎之後,如果團隊成員仍有時間繼續發展專案,Lablab.ai Hackathon 提供申請加速器的機會,可以進一步申請 Seed money 或是 A money。
講者團隊在獲獎後因為成員們都太忙無法繼續走下去,但因為這次黑客松(Hackathon)大家也都維持很好的友誼,可以持續在 Linkedin 上面關心彼此在各國開發技術上、商業營運上有什麼新消息,能夠有更全面的資訊去瞭解這個世界上各地發生的事情,是個很寶貴的經驗。
Q&A
Q1:請問要如何精進用英文跟隊友溝通技術的能力呢?
A1:講者在美國待過 9 年多,所以英文程度是可以順暢跟隊友溝通。
如果在台灣土生土長沒機會出國,講者建議 chatgpt 最近也有一些 library 可以練習英文對話,或是在找工作的時候可以找能使用英文的公司,讓自己沈浸在英文的對話裡,講者的公司也有積極往外擴展至新加坡、越南、日本的計畫,如果有興趣的聽眾/讀者,可以直接 google 講者”jason tc chuang’的名稱聯繫講者。
Q2:如何找訓練資料?
A2:講者在簡報上有分享三個 data set ,在短期的黑客松活動建議還是找現成的 data set,因為沒有時間可以人工去標記
- Search existing research dataset
- In our summarization related dataset
- Final financial summarization dataset
如果是黑客松之外的場景,Amazon好像有一個專門做 lableing 的服務工具,他們好像就是找非洲的人力去做標示圖片或是影像,有些公司提供這種標記的服務,可以考慮使用。
Photo by Mika Baumeister on Unsplash
Q3:請問當時怎麼決定哪些人比較適合當隊友? 除了能力面的評估以外還做了什麼評估?
A3:當時講者是強調自己的技術背景,並且分享出個人履歷,在找人的時候也有強調是為了贏得比賽才參加,不是玩票性質,另外要確定黑客松的 7 天內隊友們都是能排出時間參加。
講者坦言找隊友還是有點吃運氣,但還是可以靠著慢慢累積黑客松獲獎的經驗,讓自己的能力越來越強,也就越能找到相對應能力強大的隊友加入團隊。
Q4:我是經濟金融背景,可以寫一點簡單的 python,上過台灣人工智慧學校經理人班,所以對AI有一點概念,但 technical 方面很弱,這樣的背景適合做隊友嗎?
A4:適合,但前提是你要很清楚知道自己在金融領域專長的主題是什麼,金融領域的題目很廣包含法遵、風險控管、申請貸款…等。你可以找相關的題目並且明確告知團隊你就是擅長金融領域的問題,去貢獻長處。
AI 是個很活的工具,可以應用在財管、商管、行銷…等領域,所以你只要擅長某個領域,懂一點 AI 概念,再跟懂 AI 技術的成員一起合作,就可以組隊參加黑客松。
Photo by Mika Baumeister on Unsplash
Q5:在你的經驗中有什麼訓練 GPT-3 模型的技巧能分享呢?
A5:訓練GPT-3模型的關鍵是怎麼下 prompt,因為模型需要從提示文字去了解問題是什麼?答案是什麼?所以一開始需要花一點時間去做 prompt engerneering。
講者認為未來 prompt engerneering 會是滿重要的工作,最近很紅的生成式 AI 例:Midjourny, Stable Diffusion,都滿需要清楚的文字描述才能產出符合要求的結果,而這個能力是理工科比較缺少的能力,但會是文組背景的人擅長的面向,因此無論是理組或文組的人都可以各自發揮所長,共同在 AI 領域裡有所貢獻。
Q6:通常在什麼地方會看到徵求隊友的訊息?
A6:Lablab.ai 的官方 Discord 裡有一個頻道叫 looking for teammate,講者是從這個管道去看有沒有人想找隊友。或是臉書社團像是: AI 人工智慧社團、或是 Taiwan Data Science Meetup 也是一種管道可以找到志同道合的人一起組隊參加。
Q7:想問比賽過程遇到最大的困難是什麼?以及如何解決的?
A7:講者分享了兩個難題:
- GPT-3 & GPT-4 是比較新的技術,要怎麼使用精準的 prompt 從資料中訓練出答案。解決方法就是不斷去找是否有人有相關經驗,後來是團隊裡的德國成員用換句話說的方式把比賽最後一天新增的 Q&A 環節解決。
- 雲端部署的技術問題,因為講者團隊把前後端切開來,講者在 local 端測試時沒有問題,但上傳到雲端時就有發生 port 或是 instance 怎麼讓 fron-end, back-end 端跟 URL 網址進行溝通就是講者與團隊有卡關的地方。這個就只能藉由比賽過程或是工作上累積的經驗找到解決方案。
Photo by Sanket Mishra on Unsplash
Q8:想請問平常都如何在「進修」跟「工作」中做時間分配呢?
A8:講者建議在找工作時,就需要評估進修與工作的時間分配,找工作時要確定工作型態,講者建議找不會一直改 deadline 的工作,比較會有自己的時間去研究新東西,建議 ⅘ 用在工作上,⅕ 可以去研究新東西。
另外不是新創公司就一定可以玩新技術,講者建議在找工作的時候要跟主管去聊,是否有時間可以玩新技術。
Q9:這種金融資料會不會其實還是不太夠,導致訓練模型 underfiting 呢?
A9:在金融資料方面,講者分享 GPT 在處理數字資料的確比較弱,這次黑客松所使用的 Final financial summarization dataset 來玩黑客松還可以,但如果想要做到新創公司規模,還需要更多資料。講者分享 Bloomberg 有出了一篇跟金融相關的資料,應該金融相關資料會比較多。
Photo by Adeolu Eletu on Unsplash
Q10:請問在決定題目時,會先針對可能需要的 training database 做research 嗎?避免決定題目後發現沒有 data 的可能性?
A10:講者建議準備題目的時候可以準備 2 題左右,避免後續找不到訓練資料,但其實參加黑客松決定能不能獲選決賽的關鍵是選題有沒有商業價值,現在有很多開放的資料集可以使用,所以「是否有訓練資料」並不會是選題時的優先考量點。
Q11:想請問講者都是在什麼地方知道最新的 AI 消息
A11:Future tools(https://www.futuretools.io/)
Q12:請問相關hackthon的資訊是從哪裡獲得的呢?謝謝
A12:學生的話建議可以從臉書的社團、Line的社團,會提供各大專院校黑客松的訊息
已經在工作的人,可以從 Lablab.ai 上面去找,他們是歐洲的新創公司,每個禮拜都會辦一個黑客松。
講者認為黑客松是個驗證自己實力跟世界上其他工程師等級差異的地方,像 Lablab.ai 每週都有一個黑客松可以參加。講者挑的 Open AI 知名度高,參與的人數最多可以到 7000 多人參加,平常也有 2000 多人。從參加黑客松的過程滿刺激有趣的,除了驗證自己的能力之外,還可以了解其他參賽者的選題或是採用的解決方案是什麼?讓自己從中更加進步。
Photo by Danial Igdery on Unsplash
Q13:請問需要比賽比了多久才能到達目前很傑出的成績?
A13:講者上次參加比賽是 2018 年的臺北醫學大學黑客松,過了一陣子後才參加新的比賽。
因為比賽的成績是團隊共有的,講者先確保自己在工作職場上持續精進、磨練自己的技術能力,確保自己的能力足夠強大,不會造成團隊的負擔,再去找到能力互補成員,獲得最佳成績,
Q14:如果是學生的話,選擇 software engineer 還是 data engineer 的工作有什麼差異?對於職涯發展有什麼建議?
A14:這兩個都是不錯的選擇,但 software engineer 有個隱憂是 chatgpt 出來後可能會取代入門的工程師,所以你要盡快提升自己的技術升到資深,才不會被 chatgpt 取代。
Photo by Slidebean on Unsplash
Q15:如果真的要以這次比賽的結果來開一間新創公司,你覺得還需要補強的是什麼是,技術內容嗎?還是商業內容?
A15:講者認為都需要補強,因為在黑客松得獎跟推出可以在市場上獲取商業成果的產品還是有一段差距。講者之前有申像 Appworks 的加速器,這時候要看的不只是點子、技術,還要看團隊成員夠不夠強。
黑客松只是證明自己的實力,是一個起始點,但要持續發展下去需要在團隊、資金、技術、商業計畫…等方面不斷精進,因為市場與技術都是持續在變化,像之前 GPT-3 在非常短的時間出到 GPT-3.5,有可能現在解決的問題在 GPT 的迭代中間就被解決了,所以黑客松只是一個起點,還是要不斷跟上時代去打破自己舊有的紀錄。
筆記手:盧姵吟 Lavina Lu
校稿:莊子政 Jason Chuang、張晏禔 Andy Chang
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!