
[2020/07/17]Lessons Learned from Building Data Teams at Early Startups

講者簡介
📍 John Huang 現任 Lob工程團隊主管,曾經任職於 Google 的軟體工程主管以及 Handshake 的資料團隊主管,具備豐富的職場經驗,因其在軟體工程上的求學背景與在新創資料團隊擔任主管的經驗,使其對於透過資料與軟體工程協助剛起步的新創成長並茁壯成具規模的企業相當擅長。美國 University of Michigan 電腦科學工程(Computer Science Engineering)碩士,美國 University of Michigan 電腦工程(Computer Engineering)學士。
摘要
📍John 在版聚上分享在新創公司早期階段工作的心得。透過從電腦工程到資料的轉換上,能夠以 Engineer 角度為出發點,分享新創企業在早期階段會碰到的各種挑戰,對於公司 CEO 之於整個組織架構的組成,以及 CEO 之於資料科學的存在與否的判斷,John 都進行非常深度的剖析。同時,從資料團隊的角度出發,對外能指出如何對非資料專業人員做出清楚且有邏輯的溝通,對內則是如何有效建立團隊規章,並且依據本身豐富的經驗來對資料團隊的組成進行精彩的分享。
Meetup回顧
目錄:
一、新創是否需要一個資料科學團隊
二、早期新創的生命歷程
三、如何去建立一個資料團隊? 資料團隊隸屬於哪個管理層下面? 公司的核心價值在哪裡?
四、團隊的建立
五、新創資料團隊所需要的技術架構
六、John 的創業歷險
一、新創是否需要一個資料科學團隊

不同CEO對資料(Data)會有著不同的想像
- The Hype CEO: 因為資料科學現在很熱門,所以要把 AI、Machine Learning 放進全部正在使用或未來使用的專案下,原因可能是因為 CEO 希望可以透過資料科學來吸引投資者的注意或想踏入一個特別的趨勢。
- The Lost CEO: 這些 CEO 具備明確的目標,他們根據直覺或不根據資料來做決定,不透過資料或數字來確定或暸解實際發生的成本。
- The Technical CEO: CEO 知道系統為什麼會變慢,如:SQL 的運行速度很慢,使用複雜的模型,知道轉換率等指標正在下降,但無法去改善。
- The Org-Chart CEO: CEO 意識到其他公司開始建立資料科學團隊,或達到某個目標點,知道是時候成立資料科學團隊,他們很能掌握時機。
二、早期新創的生命歷程
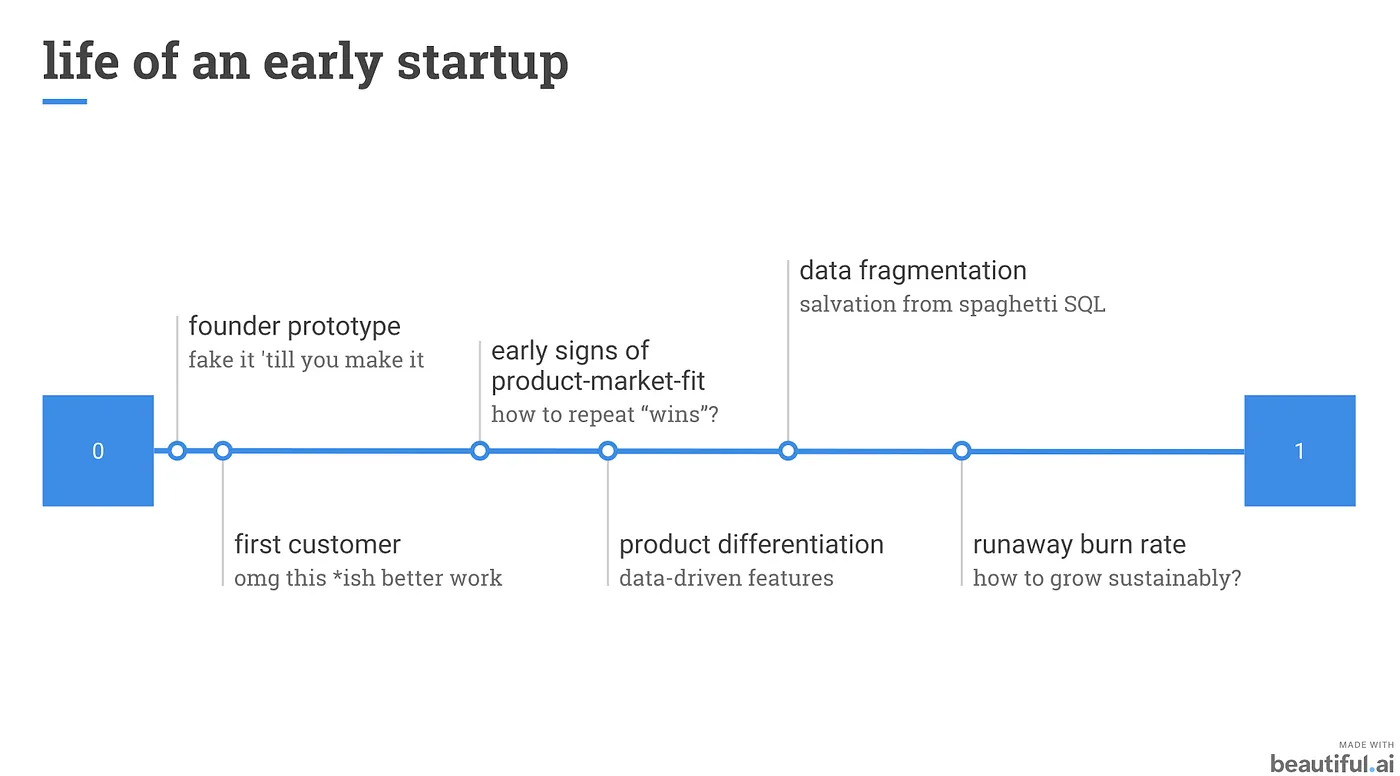
- 基本原型 :建立新創的基本原型,以拿到資金為目標,這也許並不是一個好的時間建立資料團隊。
- 第一位客戶 :有了產品,有了第一位的客戶,會去聘用更多的工程師,還不會專注在建立資料團隊。
- 穩定客戶來源 :等到越來越多的客戶開始使用產品,開始暸解自己的產品是適合整個市場的,開始思考要怎麼重複這個過程。這時候會開始需要使用資料分析,去評估如何去正確的使用資料來去提升收益或暸解商品可以如何調整以更加適合市場。
- 公司業務成長 :隨著公司成長,資料將越來越難被控制與記錄,最終產生資料破碎的問題。
- 公司業務爆炸性成長 :公司爆炸性的成長將讓使用成本消耗非常迅速。
上述(4.)(5.)的解決方法,可以和 CEO 討論這些問題是在公司生命軌跡的哪一個部分,並且試著尋找並建立可以解決問題的資料團隊。如果知道董事會成員在面對 CEO 時,會使用什麼指標來檢視公司的表現,將讓資料團隊更暸解哪些價值模型對公司會產生幫助,資料團隊也可以知道機會和問題在哪,以及如何使用方法來解決。不同的公司會有不同的核心指標來驅使其獲得價值(valuation)。
對於公司的其他部門來說,主管是否能以簡單的一句話告訴員工,「為什麼公司需要建立資料團隊」是非常重要的。如果無法正確傳達給員工,主管需要想辦法去暸解資料團隊帶給公司的價值。
三、如何去建立一個資料團隊? 資料團隊隸屬於哪個管理層下面? 公司的核心價值在哪裡?
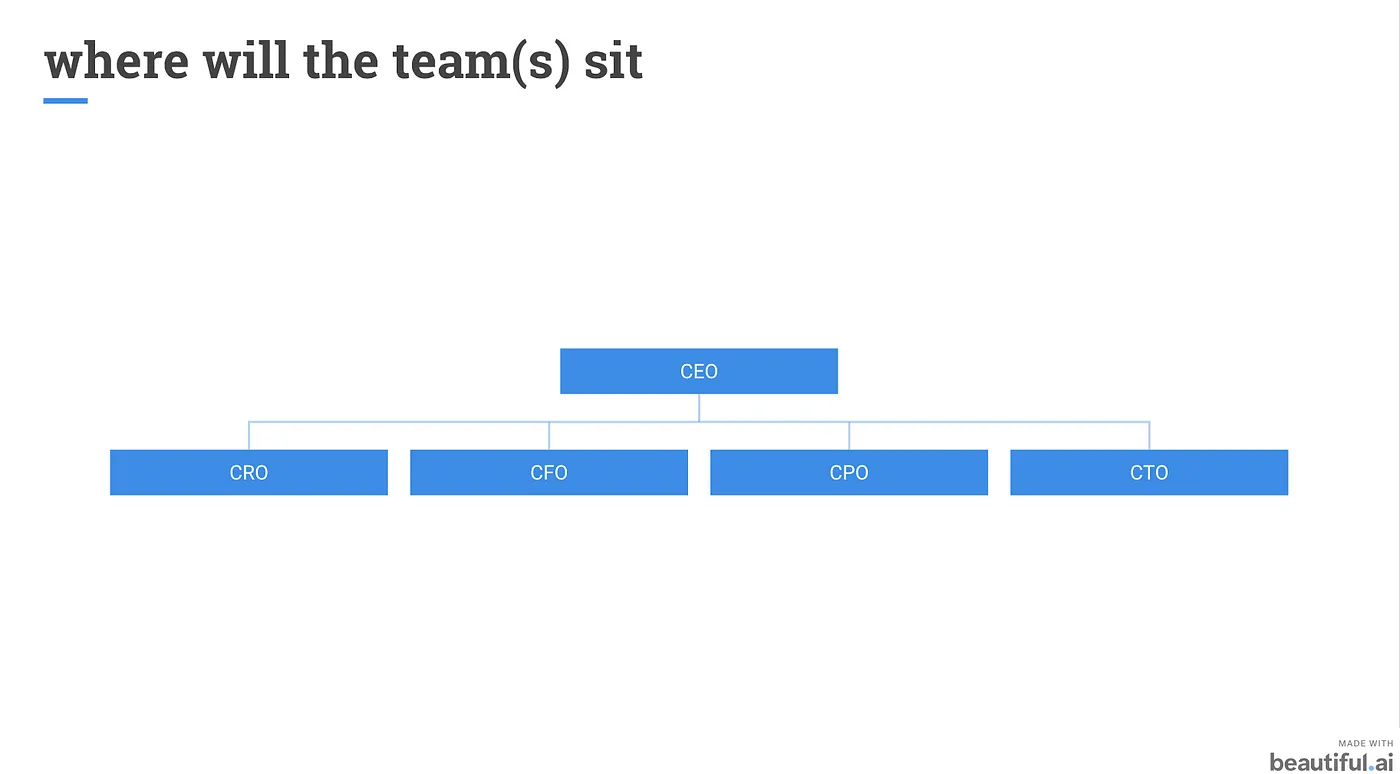
如果資料科學主要應用在產品分析或產品運用,CPO 或 CTO 應該會是比較好的歸屬。
首先設定 Team Charter 非常重要,,可以利用例如 Salesforce 的 V2MOM 架構:
- 視野 (Visions)
- 價值 (Value)
- 方法 (Methods)
- 困境 (Obstacles)
- 衡量方式 (Measures)
從經驗獲得以下四點:
- 以 Team Charter 為基準來選擇聘僱誰 :聘用你需要的人,而不是你想要的人。
- 掌控局勢 Control the firehose :在快速成長的新創,每天都會收到來自不同部門大量的要求,因此,創造流程去有效管理不同需求是非常重要的。
- 開拓道路 Carve out runway :在大公司下,專案是可以慢慢完成,但在新創的資料團隊,常常是需要內部協調,如 CFO 請你完成一個專案,資料團隊主管可以提出利益交換,要求在未來的研究專案中團隊人手不能被調整,以作為協助 CFO 請求完成專案的回報。在資料團隊底下,不一定每個產品或專案都可以發佈或有利潤產生,可能並非完全目標導向的,有可能目的是在學習或是開創新的解決方法,以開拓新的道路。
- 中心化 v.s. 去中心化 Centralized vs decentralized :
- 中心化:公司內部只有一個資料團隊和不同部門進行專案。在早期新創階段,架構可能尚未成熟,因此同屬一個團隊可以共享學習點並且會產生歸屬感。
- 去中心化: 資料科學家分別屬於不同團隊下進行專案,,可以培養專門領域。不過在架構或資料結構尚未成熟前太早去中心化的話,,也有可能造成一些資源浪費在重建資料基礎建設上。
四、團隊的建立

從大公司的工程師到進入小公司建立資料團隊,整理出以下四點經驗:
- 獨角獸是理想 Don’t hunt for unicorns :大公司的職缺時常開出高標準的工作要求,同時求職候選人可能都有非常好的學經歷,各方面都非常符合企業需求。新創若依照大公司的標準,雖然也可以找到符合的候選人,但往往無法負荷候選人開出的薪資要求。
- 新創有新創的面試法 Don’t interview as megacorps :在大公司,求職候選人非常多,因此面試的過程,與其是評估表現,更多的是在找候選人的弱點,來找理由拒絕候選人。新創招募人才,應該更重視候選人的獨特性,儘管候選人可能學經歷都沒有那麼理想,但假若他的獨特性在公司是有發展潛力,其實是可以考慮的。在新創,實踐經驗比演算法更有意義。同時,在新創中,招募經理的角色更傾向是一個啦啦隊,多多鼓勵候選人而不是讓候選人感到挫折。
- 人才招募流程 Talent pipeline :(時間不夠說明,略過此一部分)
- 招募多種類型人才 Value diversity :在早期新創階段,職務其實可以招募的很廣,越多不同職能的人可以讓公司匯聚更多好的想法。以 John 自身經驗,對於顧問產業背景的人,認為他們對於商業的敏感度是非常敏銳的,同時也觀察到 Ad-Tech 和遊戲產業背景的人非常熟悉大數據和數據分析,或者可以去消失的新創招募人才。
五、新創資料團隊所需要的技術架構 Infra
基本架構是 資料庫 — ETL(外包) — Data lake — Query/Reporting。
通常為了讓資料科學家可以快速 onboarding,Query/Reporting 的部分會讓他們能用 Notebooks 做,減少部分前置作業的障礙。
John整理出以下四點資料架構的經驗:
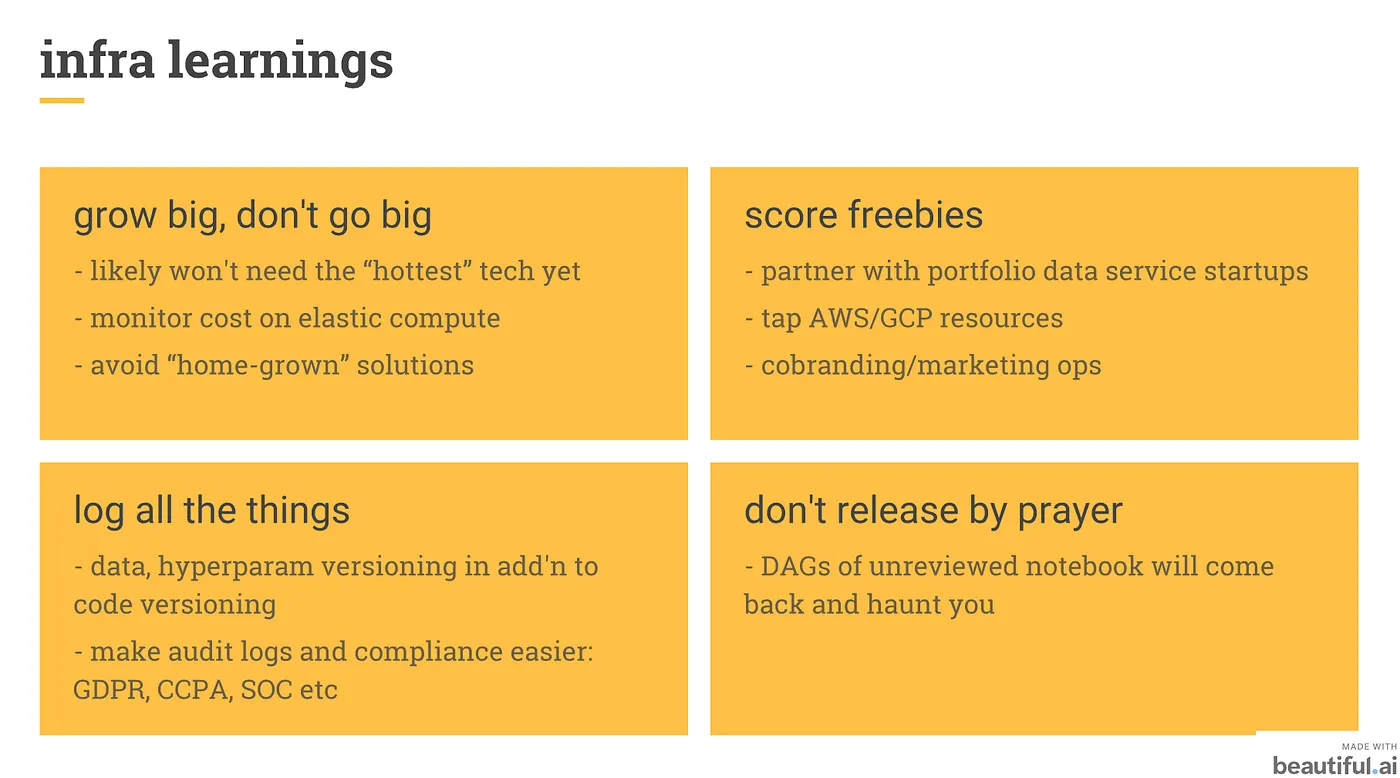
- 變大,不要變胖 Grow big, don’t go big :有些工程師或 PM 喜歡自己寫 mapreduce 或大型架構,可能在產品有需要之前就讓架構過於複雜。
👉 尚未需要使用新潮熱門的技術
👉 監控彈性計算費用
👉 避免硬刻,盡量使用業界服務
-
免費服務 Score freebies
👉 AWS 和 GCP 都提供許多免費額度給新創
👉 和其他新創一起合作來換取對方有期限的免費額度服務 -
紀錄一切能記錄的事 Log all the things
👉 在版本控制中,紀錄數據和超參數
👉 讓事件紀錄管理和合規更簡單,如 GDPR、CCPA、SOC 等等,越早開始做越好 -
Don’t release by prayer
👉 沒有管理妥當的 Data Pipeline 會在日後變得難以維護,如 DAGs
六、John 的創業歷險 Misadventure
John 分享之前做搜尋引擎的創業經驗:
一開始很簡單的想法,使用 Elasticsearch 做搜尋引擎,搜尋的成效關鍵在於使用者是否能精準輸入關鍵字。後來,John 和做搜尋引擎的人討論並研究論文,開始增添不同的演算法如 Learn to rank 等。最終,雖然有優化搜尋結果,但並沒有增加太多商業價值。
在創業過程中,可能過於專注在技術問題,而沒有認真專注商業問題,儘管如此,這對 John 來說仍是個有意義的經歷。
最後,John 提醒大家:
How do you eat an elephant?
One bite at a time.
筆記:[鍾佑偉](https://medium.com/@jacky308082)、林虹葳
校稿:John Huang、Tzu-Yi Yen、徐上雯