
Brickmaster: scenario-wise recommendation system engine & Validation
Dan Chen | Data Scientist @LINE Taiwan EC Dev

活動主辦單位:Taiwan Data Science Meetup 台灣資料科學社群
摘要
本次講座邀請了在 LINE Taiwan EC Dev擔任 Data Scientist 的 Dan Chen 來分享 LINE Shopping 的推薦系統情境以及對應的推薦系統設計,講座內容主要分成 5 段:
- Part 1 — 電商推薦系統中的情境和常見問題
- Part 2 — 推薦系統的基礎建設與資料流架構
- Part 3 — 推薦系統的驗證策略
- Part 4 — Feature Engineering, Candidate Generation, Ranking, pipeline monitoring and the goal of recommendation.
- Part 5 — QA 精選
講者介紹
Dan Chen 目前在 LINE Taiwan EC Dev 擔任 Data Scientist,專案經歷涵蓋多方領域,包含電信、金融、工廠及廣告等,並曾擔任過新創資料顧問,並著有《 Towards Tensorflow 2.0 — 無痛打造 AI 模型 》一書,本次主要介紹 LINE Shopping 的情境式推薦系統。
Part 1 — 電商推薦系統中的情境
瀏覽行為本身就帶有情境,點擊到不同的頁面也可能意味著不同的情境,如
- LINE Charts — 熱銷金榜類
- LINE Point — 點數回饋類推薦
- Search Keyword — 熱搜關鍵字相關商品推薦
- Shop — 品牌類、電商類商品推薦
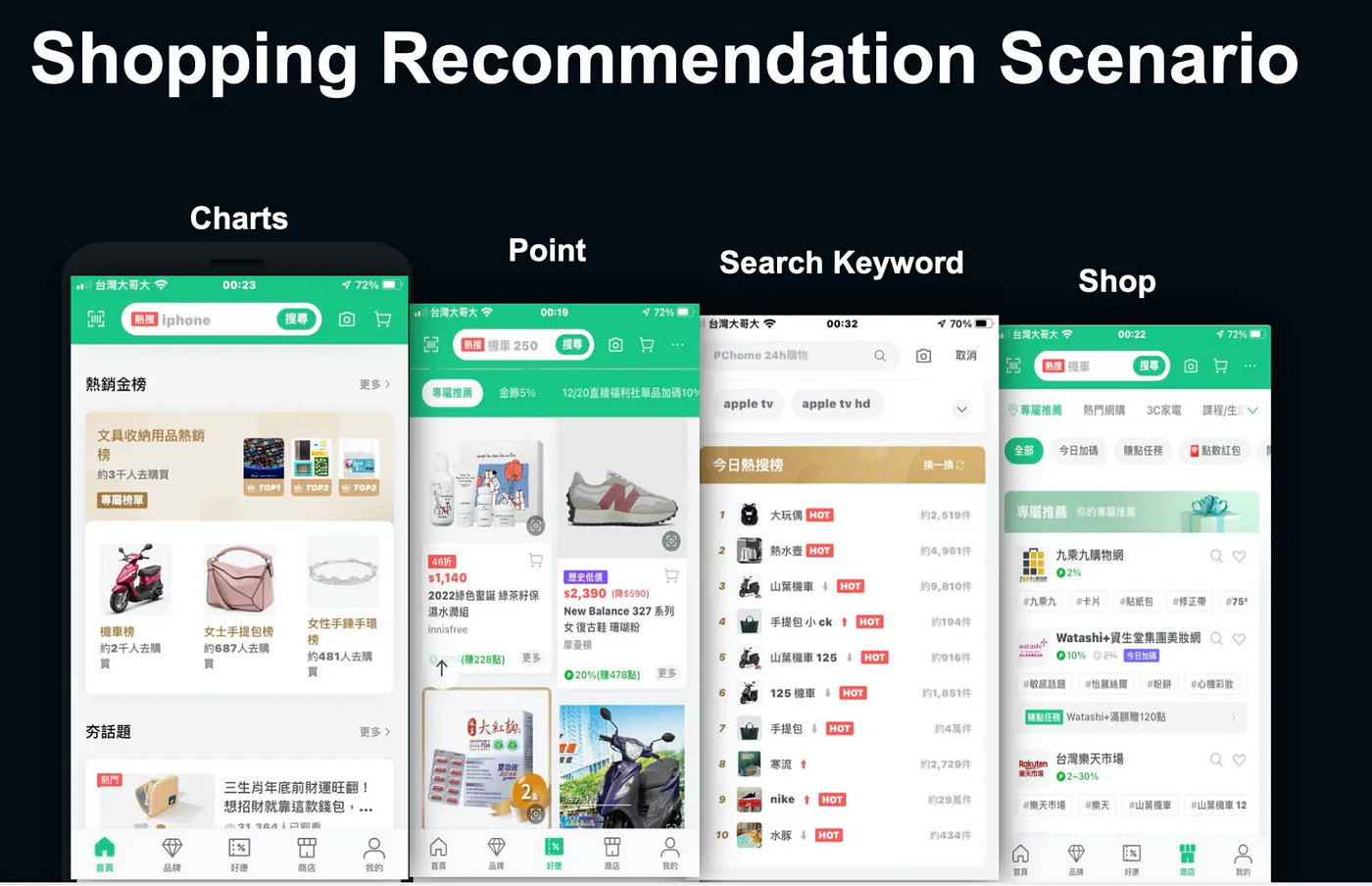
LINE Shopping 推薦場景分類— 講者投影片 [1]
電商的常見問題
Q1 : 很多商品都有容易過期的特性,電商的商品特性也不例外,新上架的商品會很熱門,而熱門期過了之後也會很快的失去熱度,然後一般推薦系統所著重的互動資料,可能還會推薦已經過熱門期的商品。
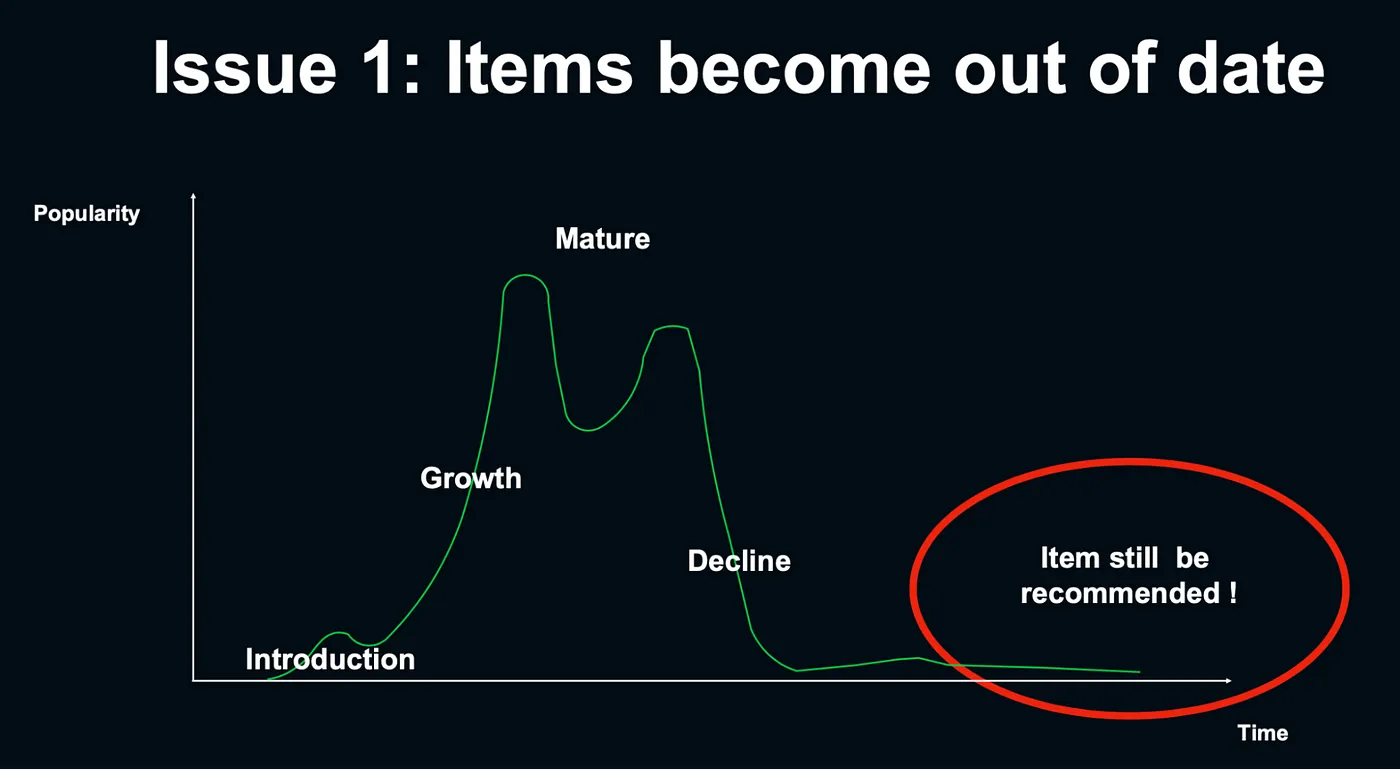
電商常見問題 1 — 講者投影片 [2]
Q2 : 難以得知使用者當前意圖,例如知道使用者喜歡 iPhone,新款 Iphone 上架了,使用者究竟是喜歡最新的 iPhone 還是上一代價格大跳水的 iPhone?
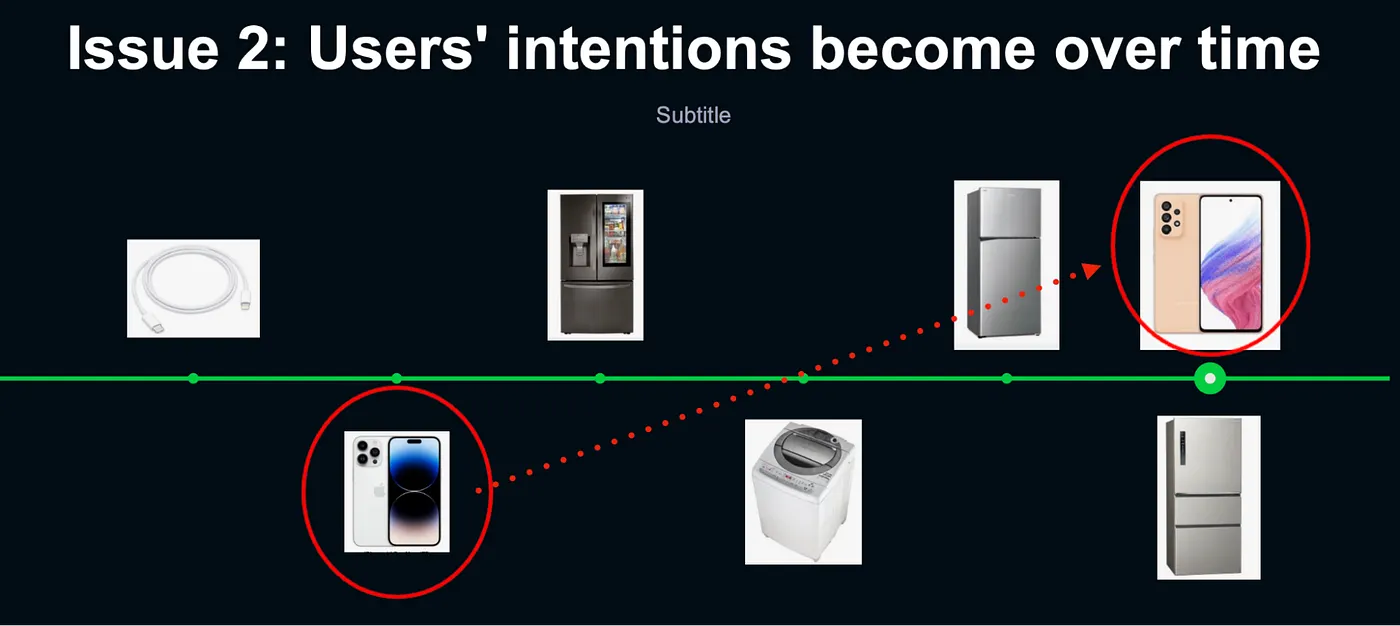
電商常見問題 2— 講者投影片 [3]
Q3 : 如何讓 Stakeholder (Planner / PM),得知目前推薦系統的成效? 如何將 Stakeholder 想要優化的指標與推薦系統做掛鉤?
由於商業場景的特性關係,LINE Shopping 使用者旅程 ( User Journey ) 中,資料顯示使用者對於 LINE SHOPPING App 有更多的互動行為( Search, View, Click ),並不等價形成轉換 (下單 / 加入購物車)。透過資料探索發現往往一搜尋就買、一 點擊就買,這對於推薦系統形成了一個挑戰。

電商常見問題 3— 講者投影片 [4]
Part 2 — 推薦系統的基礎建設與資料流架構
LINE EC Dev 內部有一套稱為 Brickmaster 的推薦系統,就是設計來解決上述 3 個問題,整體的技術架構是兩階段的模型。

LINE EC Dev 所設計的推薦系統解決方案— 講者投影片 [5]
基礎建設可拆成五個模組,Tech stack 按照計算框架 / 資料儲存 / 服務提供 / 排程管理 / ML 實驗管理,有使用到的工具如下:
- 計算框架 — Pyspark — 主要用於 ETL 拉取資料,模型訓練主要使用 PyTorch family。
- 資料儲存 — HDFS / Hive — 主要用於原始資料以及 ETL 後的中繼資料儲存, Serving 資料集則使用 Redis。
- 服務提供 — 主要使用 FastAPI 做串接, Dash 則作為 demo site 使用。
- 排程管理 — Airflow 是相當常見的排程管理工具。
- ML 實驗管理 — 主要透過 mlflow 來觀察有沒有 train 壞掉,或是其他需要處理的 issue。

LINE EC DEV Tech Stack— 講者投影片 [6]
資料流架構能拆成以下五個階段:
- 使用者會在頁面留下互動資料 — Web / App Log,原始資料又能被分為三個大類:
- User Profile — 使用者特徵 — 如性別、年齡。
- Item Profile — 商品標題 (例如什麼樣的衣服)、商品標籤 (服飾)、商品描述 (極保暖)。
- Feature Generation — 按照原始資料做 ETL,並儲存在 Hive / HDFS ,這一層的運算量是最大的,也是主要使用到 Spark 的部分。
- Candidates Generation — 從加工資料中計算出每人的商品候選清單 (例如每人 1000 品、 2000品、5000品),會根據推薦場景來決定。
- Ranking — 按照不同情境設計不同的指標進行精確排序,(例如從每人 1000品 → 每人 10品 每人100 品)。
- Serving — 從 UI 上可以看到每個人的推薦列表,從而進入曝光、點擊、特徵收集的推薦循環。
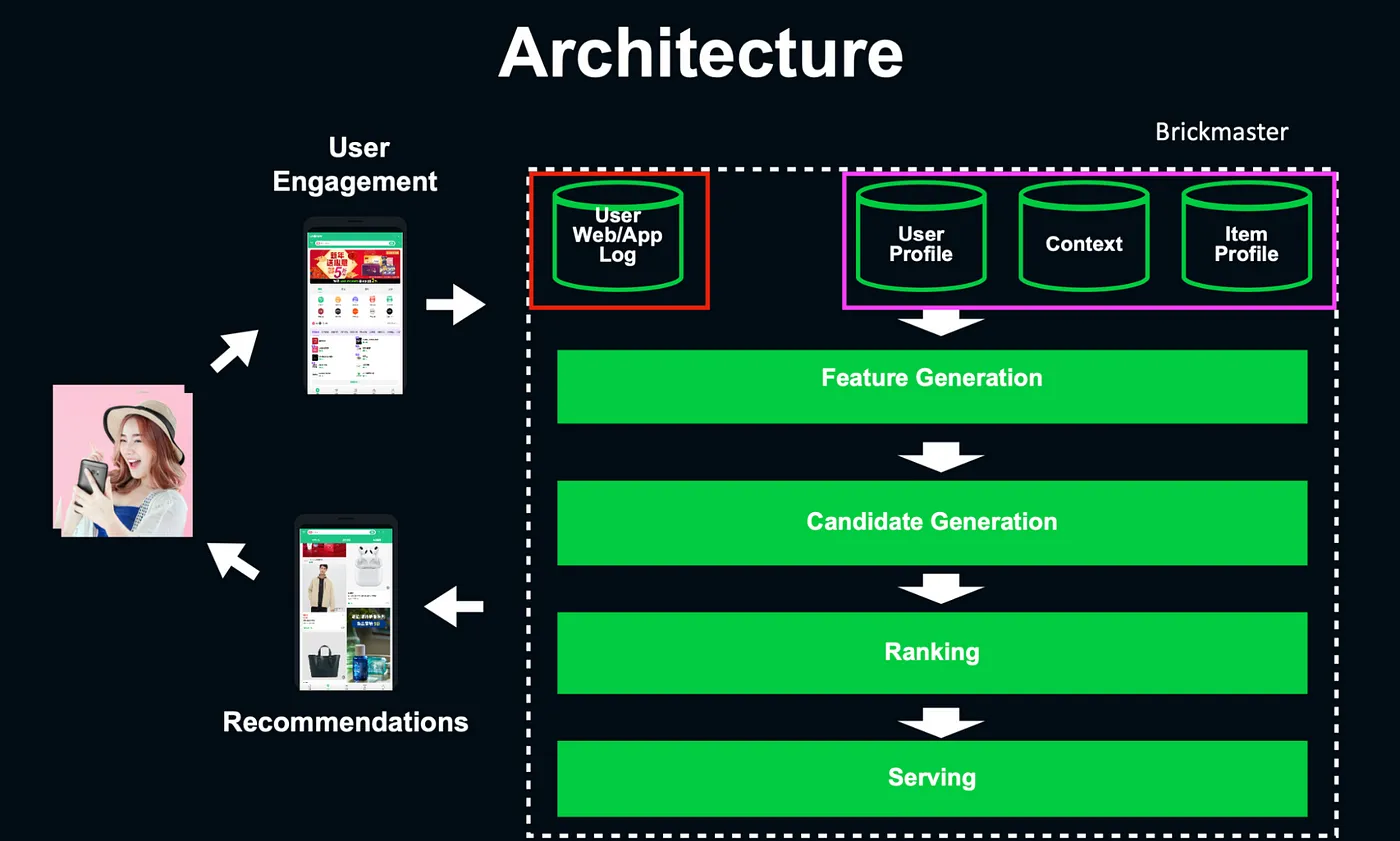
LINE EC DEV Tech Stack — 講者投影片 [6]
不同算法模組的目標也不同,如 Candidate Generation 是第一階段粗篩,所以目標會是 Recall,而非 Precision,但 Ranking 階段已經進入精確排序,就必須著重在 Precision。
根據推薦情境不同,也需要能夠針對推薦情境決定 Candidates Generation 需要粗排序的數量,例如 1000品 or 5000品,另一方面,不同的推薦情境也有不同的優化指標。
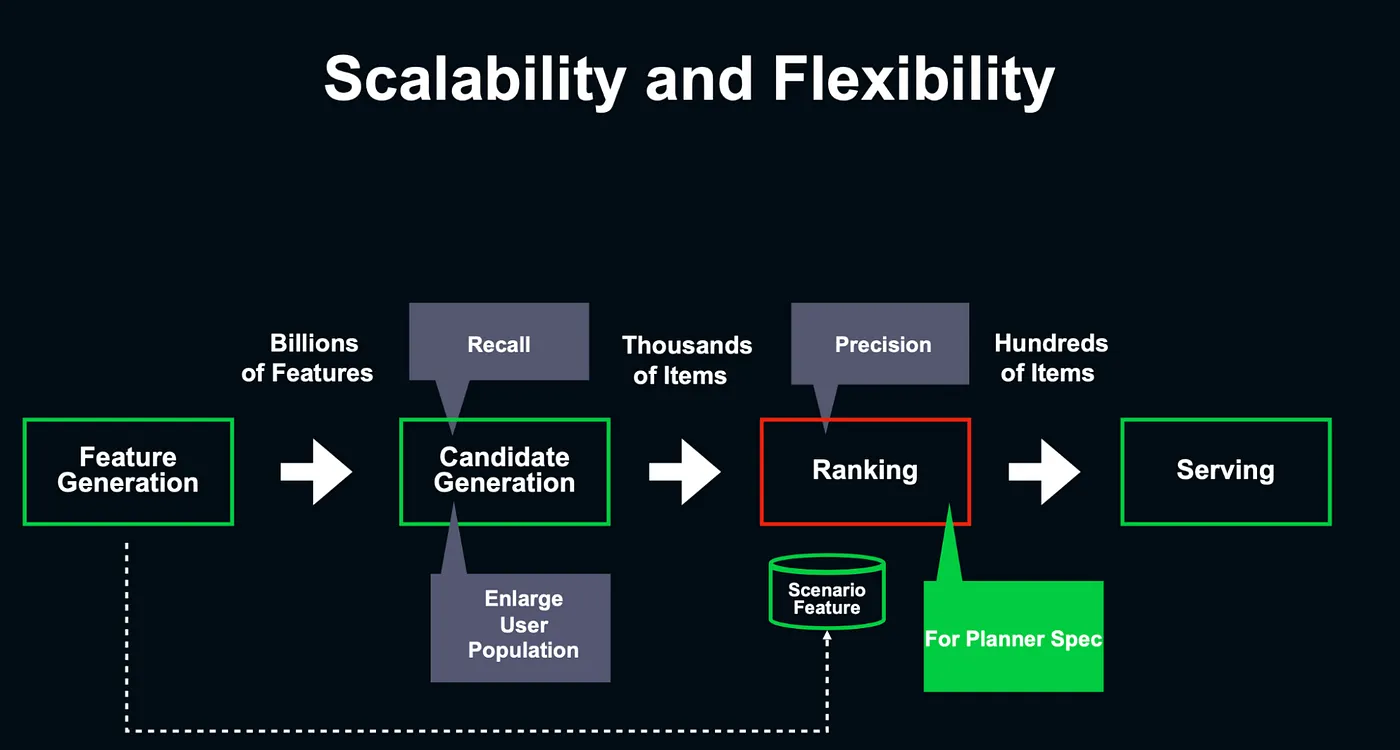
LINE EC DEV 資料流架構與側重指標— 講者投影片 [7]
Part 3 — 推薦系統的驗證策略
離線驗證
透過 mlflow 來做實驗管理,Evaluation Report 有分成以下三個 Metrics,如果發現相關指標大幅下降,就會請相關職能的人員協助:
Model metrics — Top-N metrics (e.g. MAP, NDCG):
- Data Engineer / Machine Learning Engineer / Data Scientist
Business metrics — CTR, CVR, GMV:
- Data Scientist
Overview metrics — Diversity / Coverage:
- Data Scientist
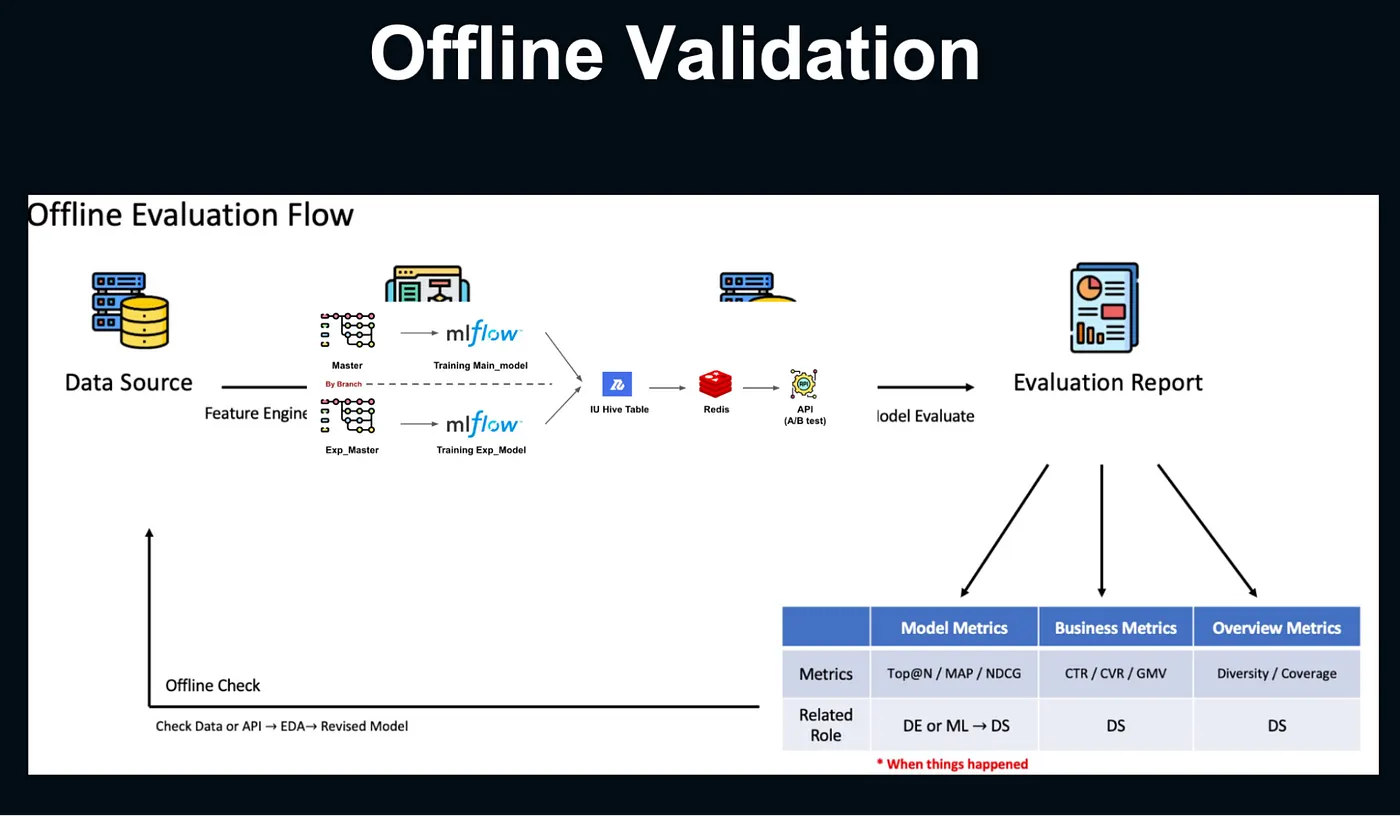
LINE EC DEV 推薦系統離線驗證流程— 講者投影片 [8]
線上驗證
A/B Testing — 雖然市面上有很多的服務,但基於公司內部的政策,由 LINE EC Dev 團隊自己搭建的,目前都還需要人工設定,還沒有進行完整自動化。

LINE EC DEV 推薦系統線上驗證流程 — 講者投影片 [9]
Part 4 — Feature Engineering, Candidate Generation, Ranking, pipeline monitoring and the goal of recommendation.
Feature Engineering
- 特徵工程中有許多特殊的方法,也有許多細緻的分類,以 Product Profile舉例,商品描述需要審慎思考哪些字詞是有用的,哪些沒有。
- 節慶特徵則是講者認為相當有趣的經驗,送禮上很容易跟節慶結合,也試過農曆年的特徵。
- 情境特徵包含如上次點擊時間、廣告觀看時間等。
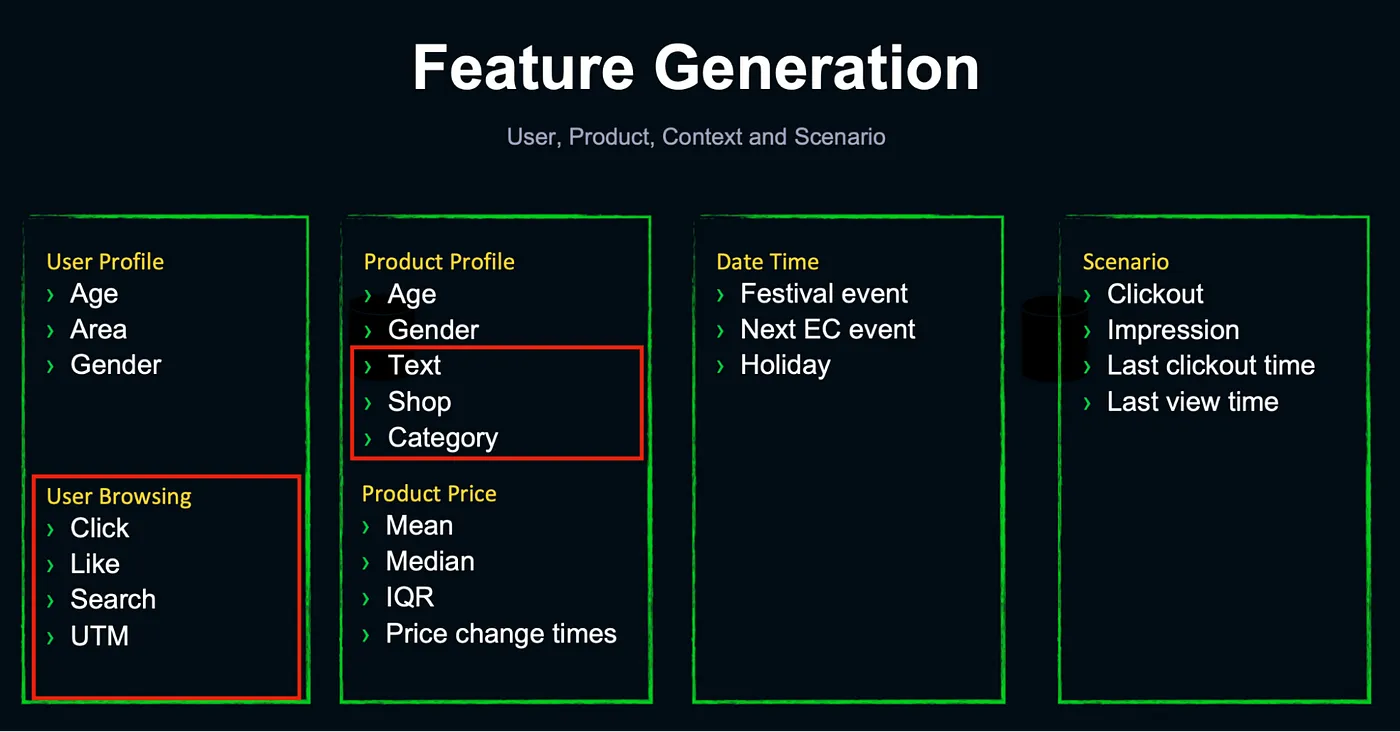
電商推薦系統特徵與原始資料分類表— 講者投影片 [10]
另一方面,文字特徵需要特別做處理,多半聚焦在商品名稱和商品描述:
- 商品名稱 — 由於 Token 直接做 one hot encoding 維度會爆炸,因此採用 embedding 的做法。
- 性別指向性商品 — 有的商品具有性別指向性,如買女性內衣的顧客有很高的機會 (但並非 100%) 會是女性,因此性別指向性商品能夠反推購買者的可能性別。

電商推薦系統特徵與產品名稱處理流程— 講者投影片 [11]
Candidate Generation
LINE Shopping 的點擊和其實和廣告很像, CTR 偏低,因此在資料預處理上也需要一些手段來增強訓練成果 (如 negative sampling),在目前的實驗中,類 YouTube 的 DNN 有比較好的表現。
在推論階段,由於計算複雜度的關係,資料量大的情況下會採用 Locality Sensitive Hashing 的技巧將 User Embedding 和 Item Embedding 做媒合,產生 Candidates。
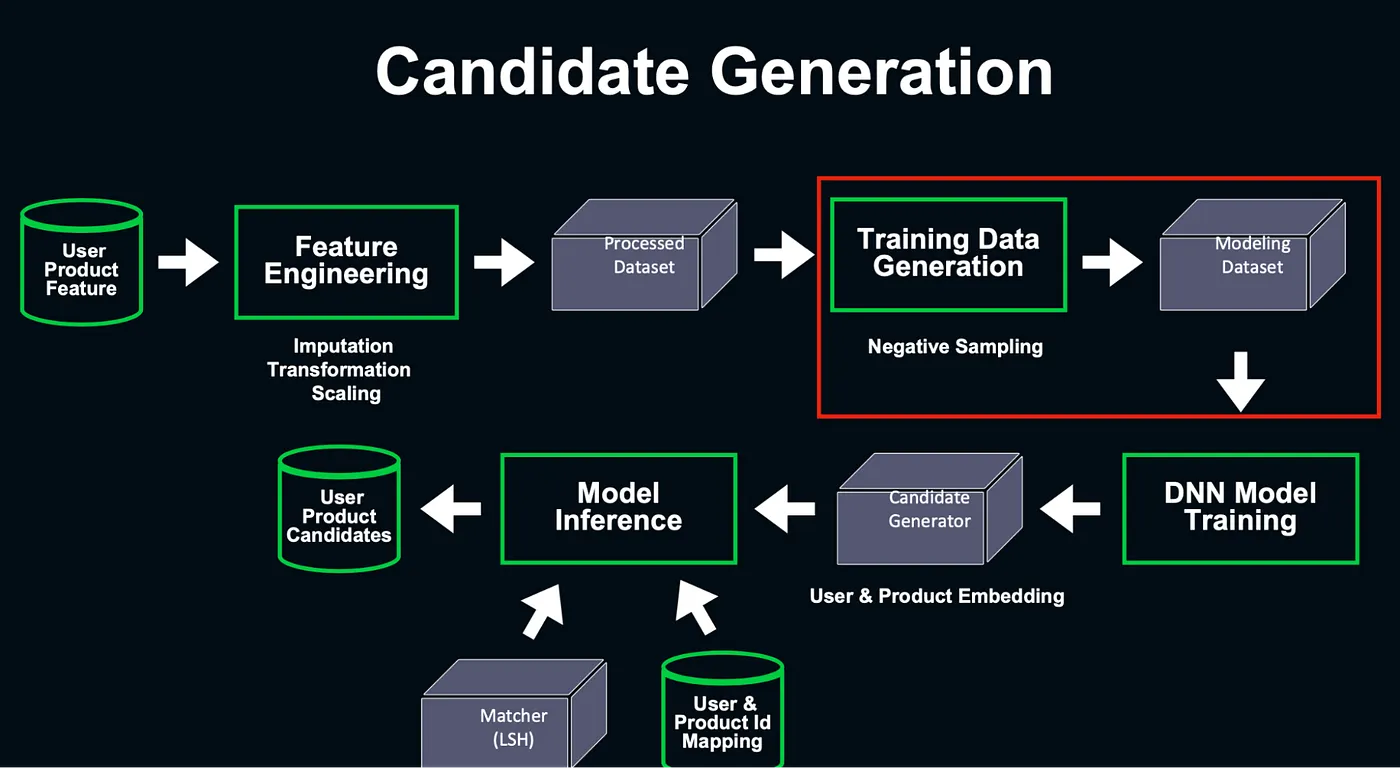
電商推薦系統 — Candidate Generation — 講者投影片 [12]
Ranking
排序階段主要會將排序目標和 Stakeholder (Planner, PM) 的專案目標對齊,並設計適合的特徵,例如有的場景更關心使用者點擊量,那麼須將優化目標調整成最小化下次點擊時間,有的場景希望使用者 和 App 互動更多,則最大化使用者的 Session Duration。
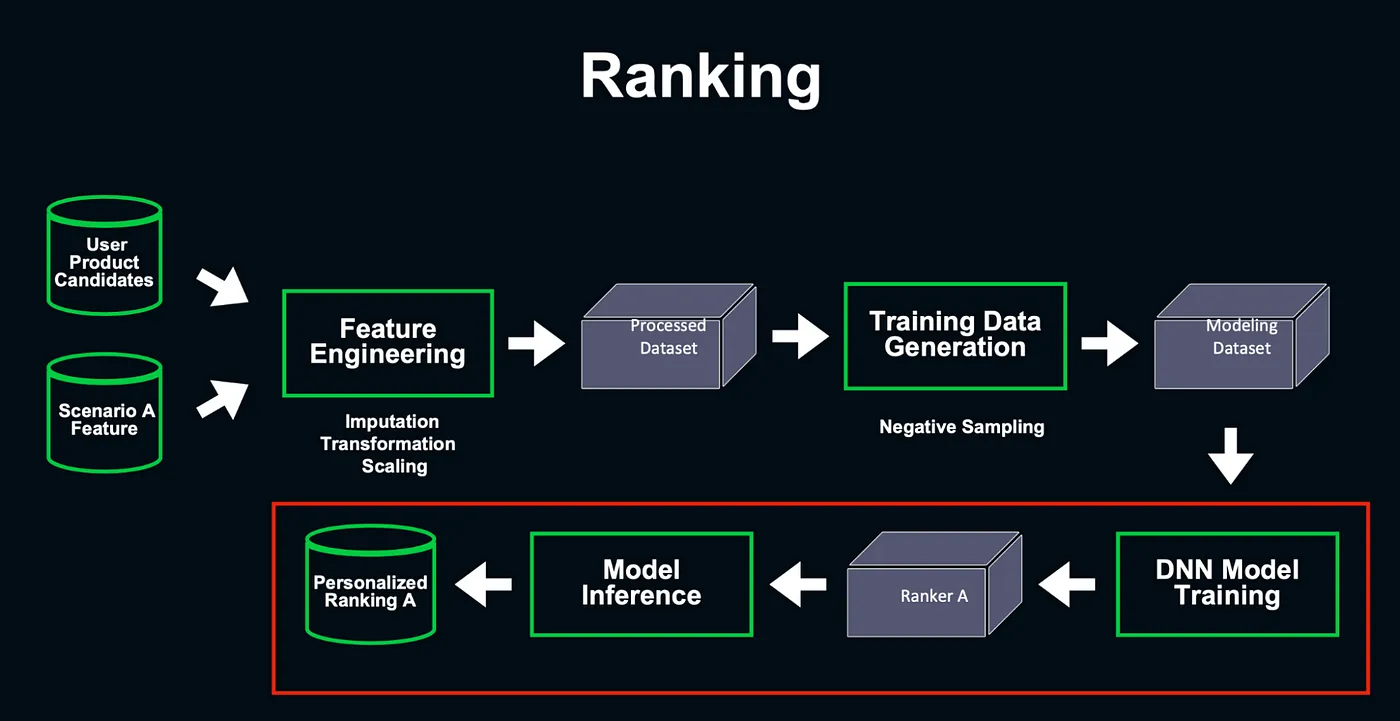
電商推薦系統 — Ranking— 講者投影片 [13]
Monitoring
穩定性除了會監看 DAG 的執行狀態,也會看缺失值、outlier 是否過多,超過一定的標準就會發出 slack alert。
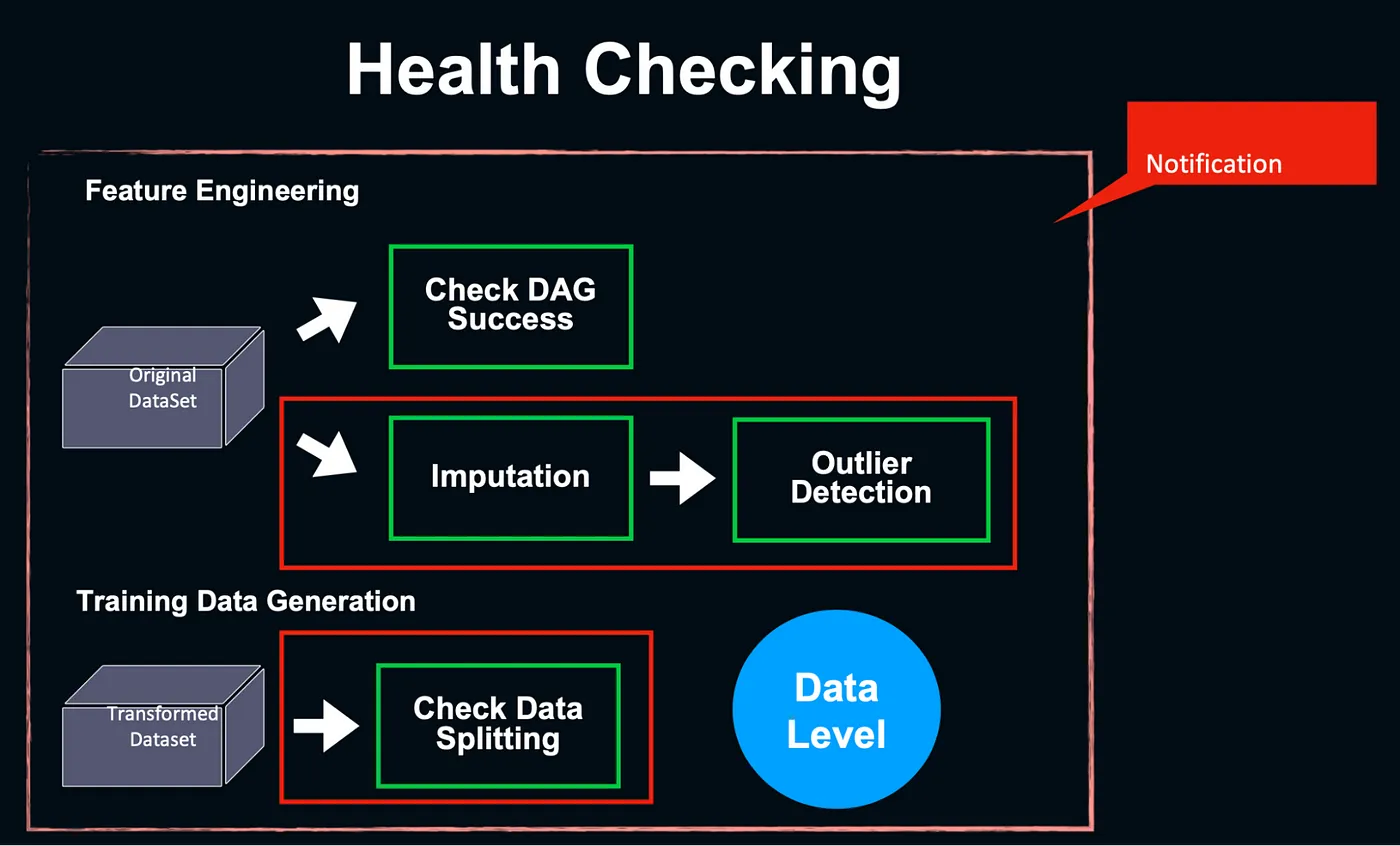
電商推薦系統 — 資料品質檢測— 講者投影片 [14]
Goal of the recommendation system
總結來說,在 Candidates Generations 時,主要關注的是使用者興趣,系統是否能找出使用者會有興趣的商品,而在 Ranking 階段,不同的場景會有不同的優化目標,就能進針對不同目標進行排序。
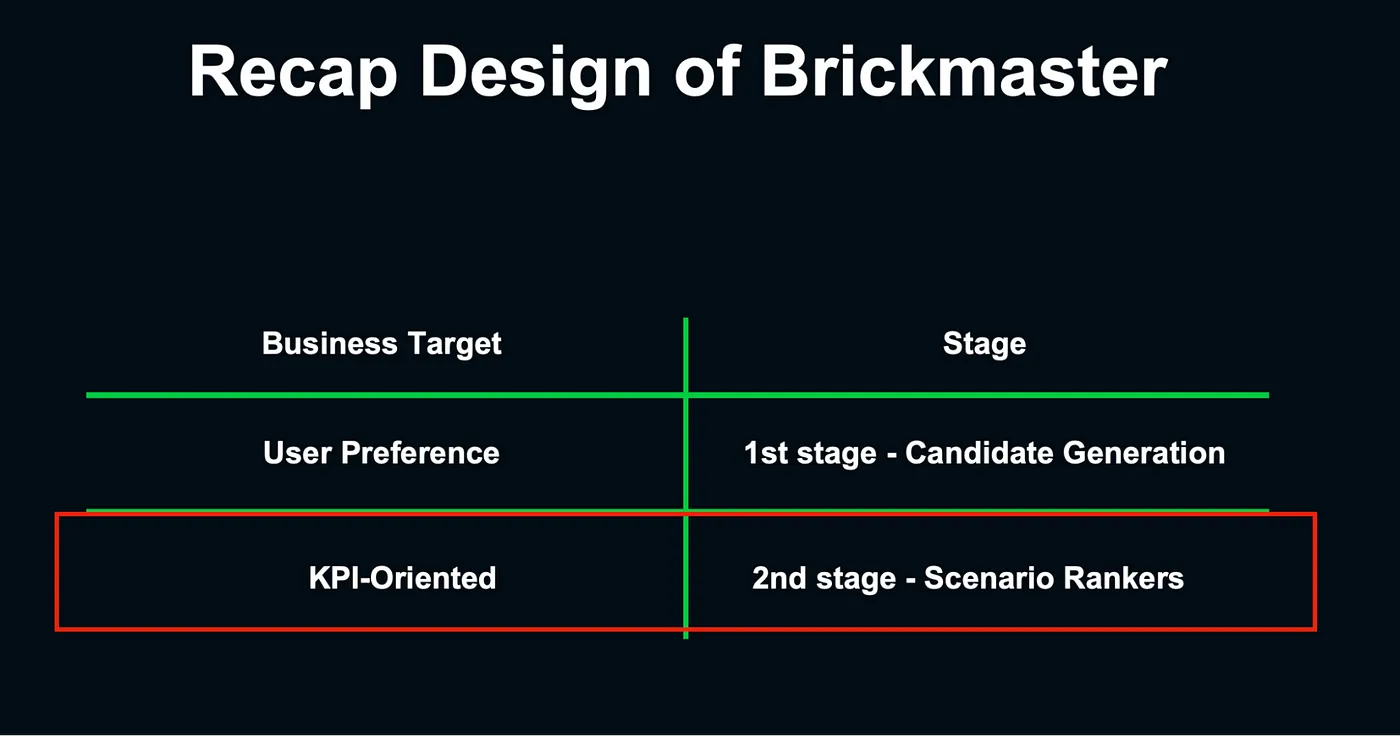
演算法架構和商業目標對應表— 講者投影片 [15]
設計推薦系統時也期望媒合到商業目標,如希望點擊量提升,可設計成最小化下一次的點擊時間差,如果是希望增強使用者互動,則會最大化 Session Duration。

將商業指標轉換為推薦系統問題對應表— 講者投影片 [16]
Part 5 — QA 精選
Q1. 想請問電商場景中,使用者興趣變化非常大,模型訓練的頻率?
- Ranking — 每天 re-train
- Sourcing — 每週 re-train
- 主要的考量是資料量和計算資源的考量
Q2. 是否有特殊的特徵萃取工程,以及 User, Item 如何做選取,來避免維度爆炸?
- 會採用過去 N 天內活躍的 User, Item,來避免 User, Item 過多,也會搭配 embedding 來做使用。
Q3. 根據你們的架構,是否有使用到 realtime 的推薦呢? 還是主要是先算好推薦結果,再進行 Serving?
- 目前的架構設計,是先算好再進行 Serving, Candidates Generation 是 Weekly Retrain, Ranking 則是 Daily Retrain, realtime 也是我們很想嘗試的一塊。
Q4. 如何衡量 diversity / coverage?
- Diversity — 以 product category 作為 dimension ,測量 entropy,entropy 可測量推薦分佈在 category 的分布是集中或是分散。
- Diversity 對於離線驗證相當有幫助, planner 在離線驗證時,如果覺得常常推薦出來的內容都很像,會反映在該指標上。
- Diversity / Coverage 比較沒有一個精確值,都是看長期分布比較多,或說一個新的模型不要真的 diversity 過低即可。
- 如果擔心預測的類別都很類似,例如都很熱門,或者都是 iPhone 14,那麼就針對該類別設計分層,例如熱門度分層,iPhone 品類分層等,一樣可以用 entropy。
Q5. 如果提升了 CTR,但整體使用者體驗下降 (如購買金額、或者商品頁閱讀完成度),會怎麼處理?
- 跟 Planner 討論,如果 Planner 覺得 CTR 很重要,但購買金額下降,是否可行,中間是否一些需要討論的空間,講者認為,這段溝通也是 Data Scientist 的一項重要工作以及能夠體現 Data Scientist 的價值之一。
筆手 : Joe Tsai