
得民心者得天下: How do we build an opinion mining system from scratch?
Sean Chang, Sr. Data Scientist@KKLab
講者介紹 - **Sean Chang** 台大經濟所畢,不務正業跑來當了工程師。除了喜愛資料科學以外,也熱愛研究前後端與DevOps。現任職於 KKBOX Group 旗下子公司,KKLab 在研究發展中心擔任 Sr. Data Scientist,主要研究範圍為自然語言處理。
本次主要分享KKBOX使用的輿情觀測系統,如何建置模型。
http://seanchang.live/>
Abstract:
自然語言處理近年來成為熱門的研究主題。 在現今人手一台智慧型手機的時代下,人與人的交流大部分都變成了通訊軟體的訊息、各大社群網站的留言,所以讓電腦讀懂人類的語言也變成了一件相當有價值的事情。 KKBOX 在2018年搭上了這波潮流,我們從無到有、披荊斬棘,踩了大大小小的坑以後,累積出了許多 NLP 相關的知識與技術,並將這些累積下來的心血應用在集團內外各種大大小小的專案。 在這次演講將與大家分享我們在集團內部使用的輿情分析系統,以及我們在建置這套系統時所遭遇的各種挑戰。

Sean 主要分享 KKBOX 使用的輿情觀測系統,如何建置模型
KKLab 2019年成立,目的為聚集高端技術人員,作為公司創新的內部加速器或孵化器的模式,提供公司新事業的技術支援或是 AI solution,也會與外部公司接洽合作。
KKLab 日常研究主要有以下四種領域

**Speech & Audio
**Audio classification 是他們與中研院作的專案,不只可以預測演唱者,也可以找出歌曲中的特色有哪些,Demo 吳卓源重新編曲放入分類後,還是可以分辨出來演唱者的 ,下方的雷達圖可以偵測歌曲中這段的特色有哪些。

**Natural Language Processing
** Song Intelligence(Hit Song Prediction) 可以分析歌曲會不會紅、什麼時候會紅,以及 Model 歌手生涯路線。
下方左圖為分析歌曲受到群眾喜愛的原因,以及各項原因的占比。
右圖為 Model 歌手生涯路線,橫軸:群眾網路, 縱軸:黏著度。
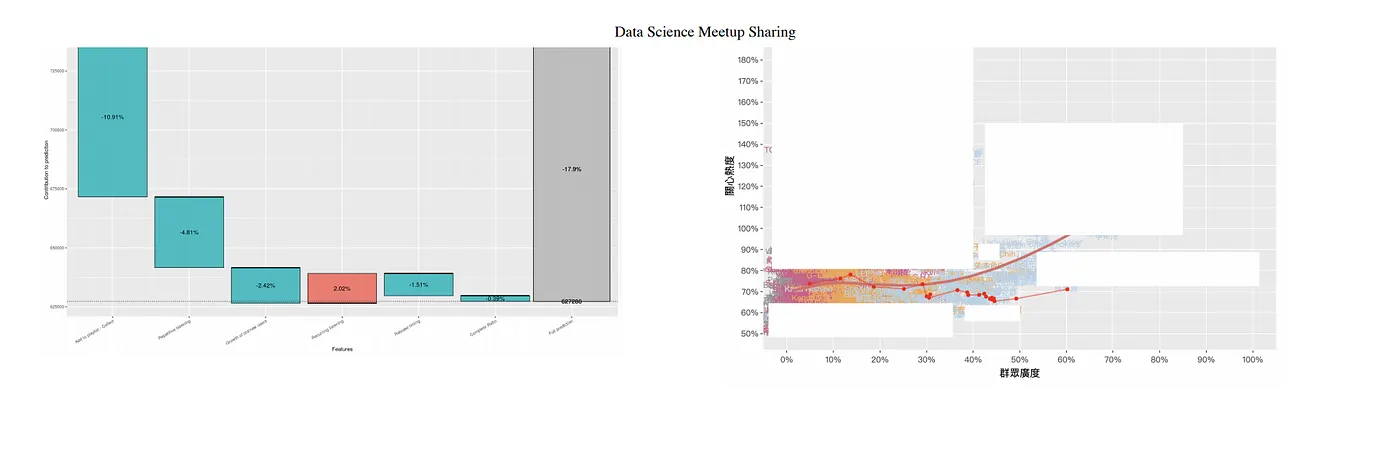
除此之外,NLP 工作也包含了 App Review 分類、AI 歌詞創作以及各種外部合作。而外部合作是與音箱合作,提供 API,讓用戶語音輸入需求,再提供相對應的內容。
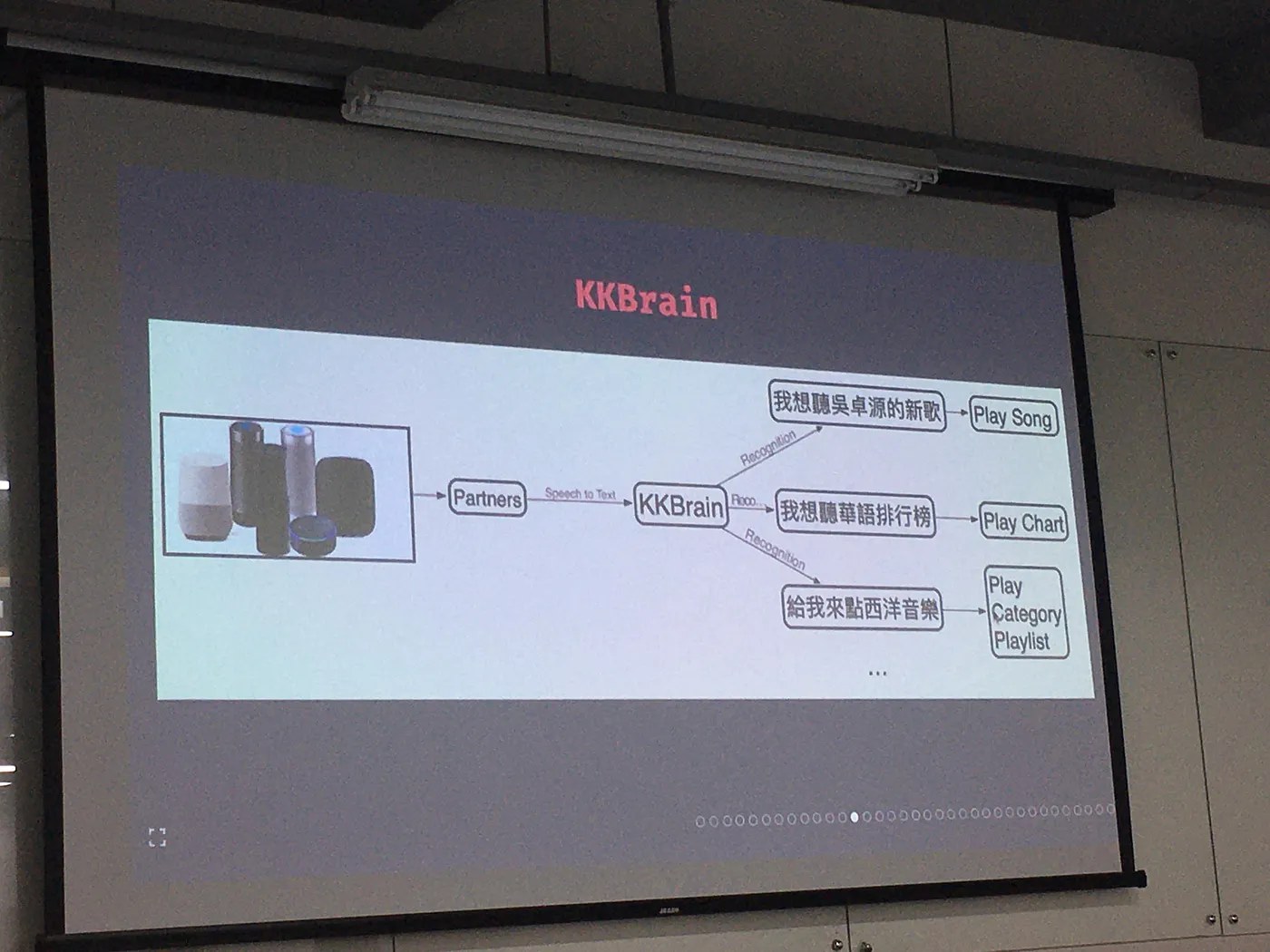
**Recommendations
** App 中推薦歌單、日本產品的部分與文章推薦。
**Data Mining & Modeling
**除了對於產品功能的分析,我們也有對於歌曲會不會紅、演唱會銷售及用戶流失分析。
輿情分析
分析主要包含三大項: Named entity recognition(NER)、Text classification、Sentiment analysis。
Named entity recognition(NER): 吳卓源 person預計 2020/9/12 date __ 在 Legacy Max location舉辦演唱會 event。NER 主要是用來把人、時、地與活動等資訊標記出來。辨認出來後,我們就可以做很多事情,大家可以想像一下可以如何運用這資訊。
Text classification: 在 PTT 上面其實很多文章是在進行票務交易,像是在跨年前一週這類型文章會增加,因為很多歌手在跨年時會舉辦演唱會,這些資訊對於票房分析很有幫助。
Sentiment analysis : 今天演會吳卓源Positive也唱太好了吧! 回音有點嚴重 Negative — >對於歌手給了正面的評價,但是對於場地的評價為負面。

System Structure
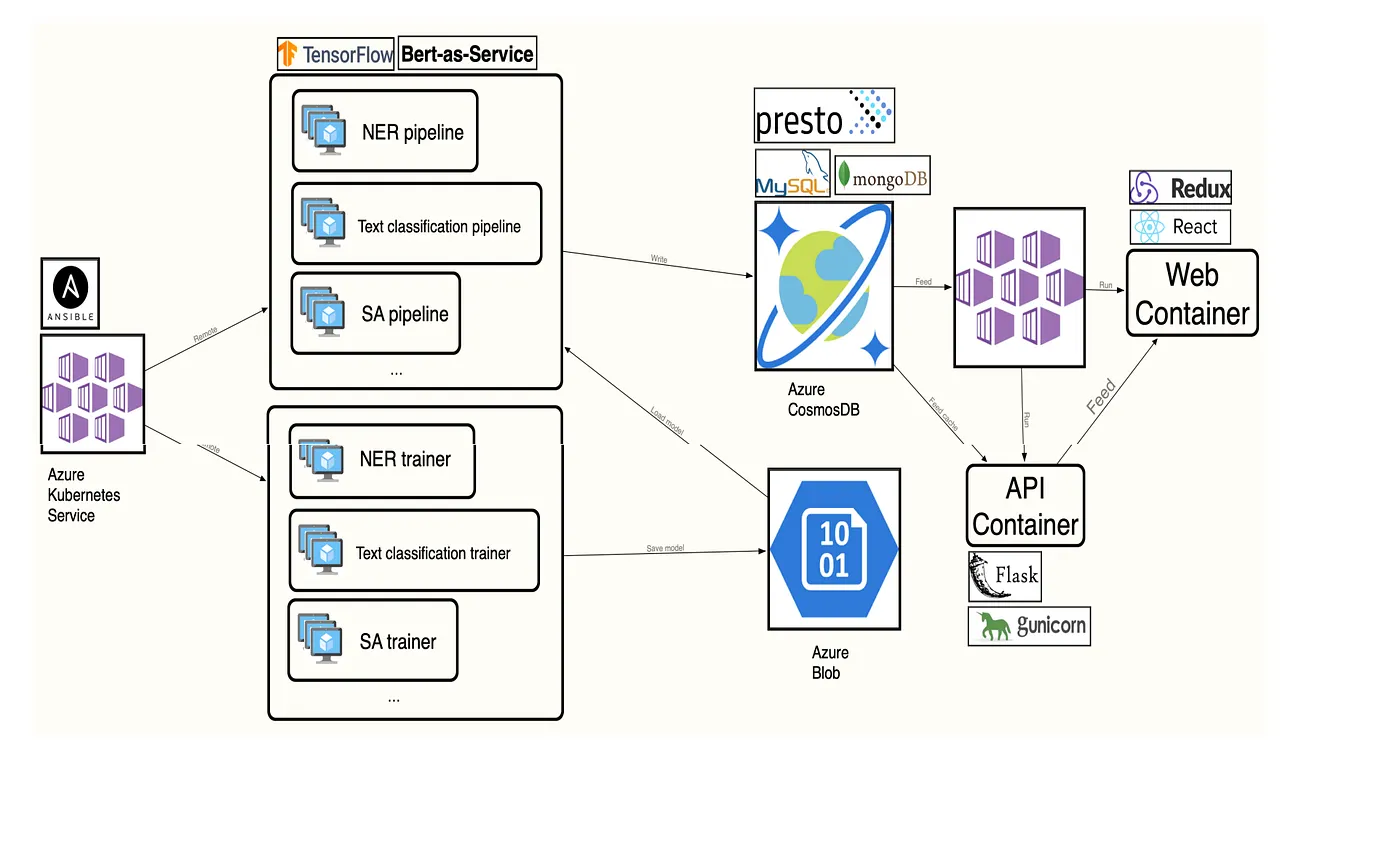
我們 1 年前設計時是使用 AWS 的服務,現在公司與 Azure 合作,所以已經轉移到 Azure。我們會在 Azure 上面運行,去開各種訓練模型的機器,訓練完後我們會把模型存到 Azure Blob,Azure Blob 提供模型給 NER、Text classification 與 SA Pipeline,主要使用 TensorFlow 以及 Bert-as-Service,再用 API 放到前端呈現。目前系統只供內部使用,不排除未來有可能發展成 SaaS 服務。
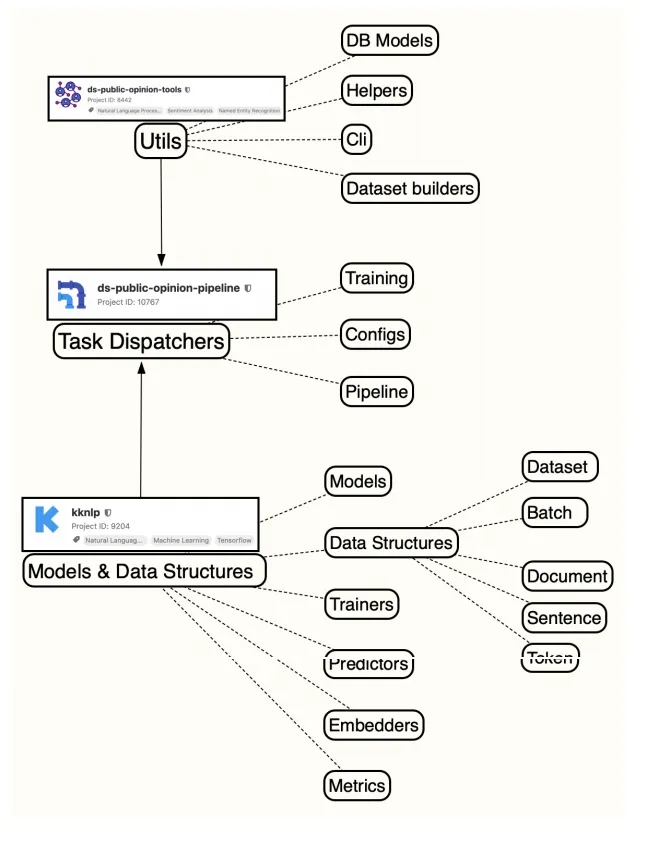
其實背後使用 3 個資源,第一是包含了所有 Datasets 的 Utils,第二個 Task Dispatchers 也就是所有演算法的模型和訓練,最後就是 Models & Data Structures,主要使用的 Data Structure 為 Document、Sentence 與 Token。
KKNLP 的設計是將 Raw Data 餵到 Data API 中去跑 Trainers 或 Predictors ,最後透過 Metrics 去衡量模型。KKNLP 設計理念是將最底層的 Lanaguage Model 建 Embedders 後,再去做 NER、Sentiment 等各種分析,最後用 TensorFlow 建模型。
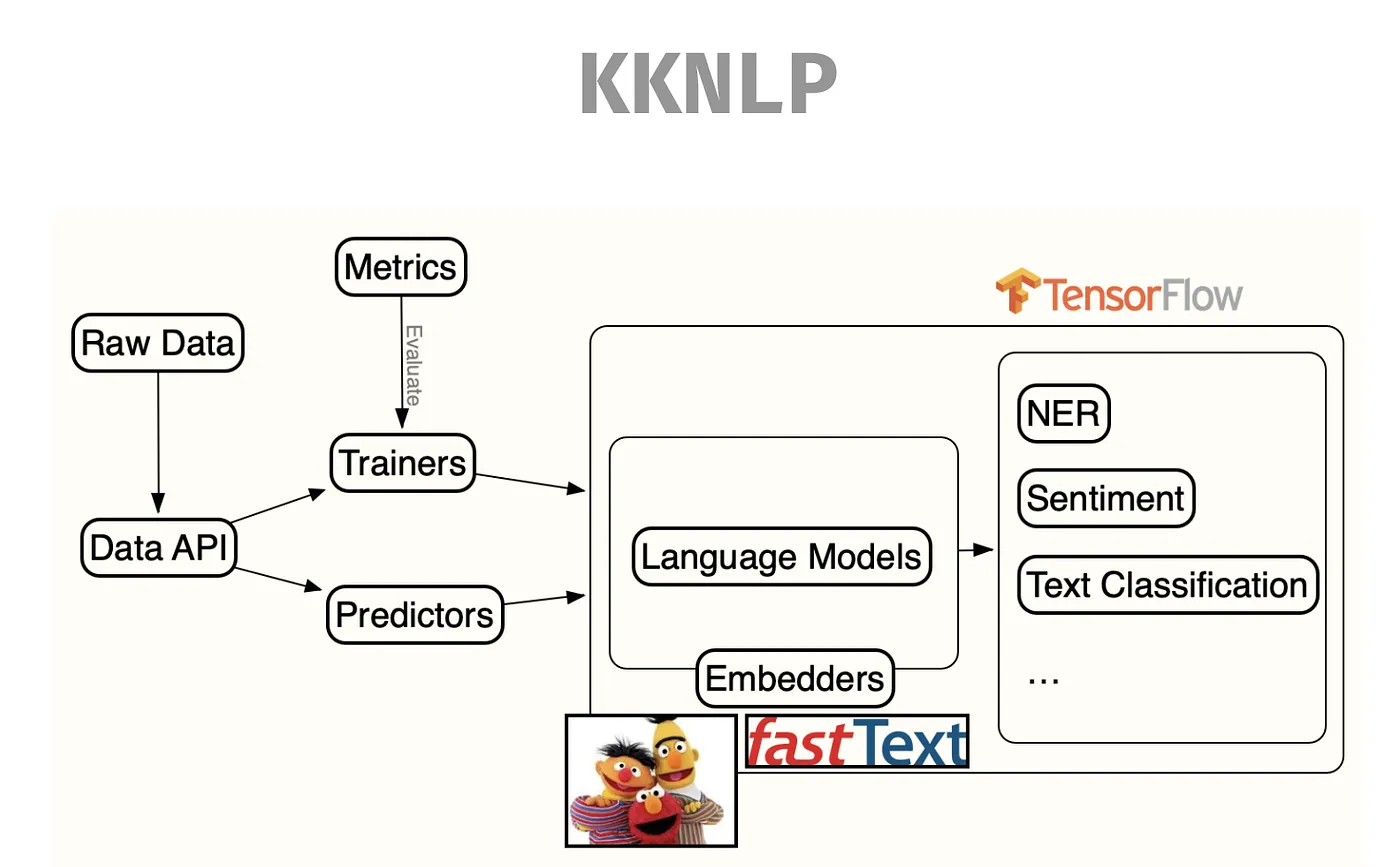
在 Training 時,只要 New 一個 Model 把 Embedder 塞入 Trainer 裡面就完成了,在訓練、測試與維護上相當的方便。
Sean 的貼心提醒:模型需要進行 AB Test,以免有一些副作用產生。

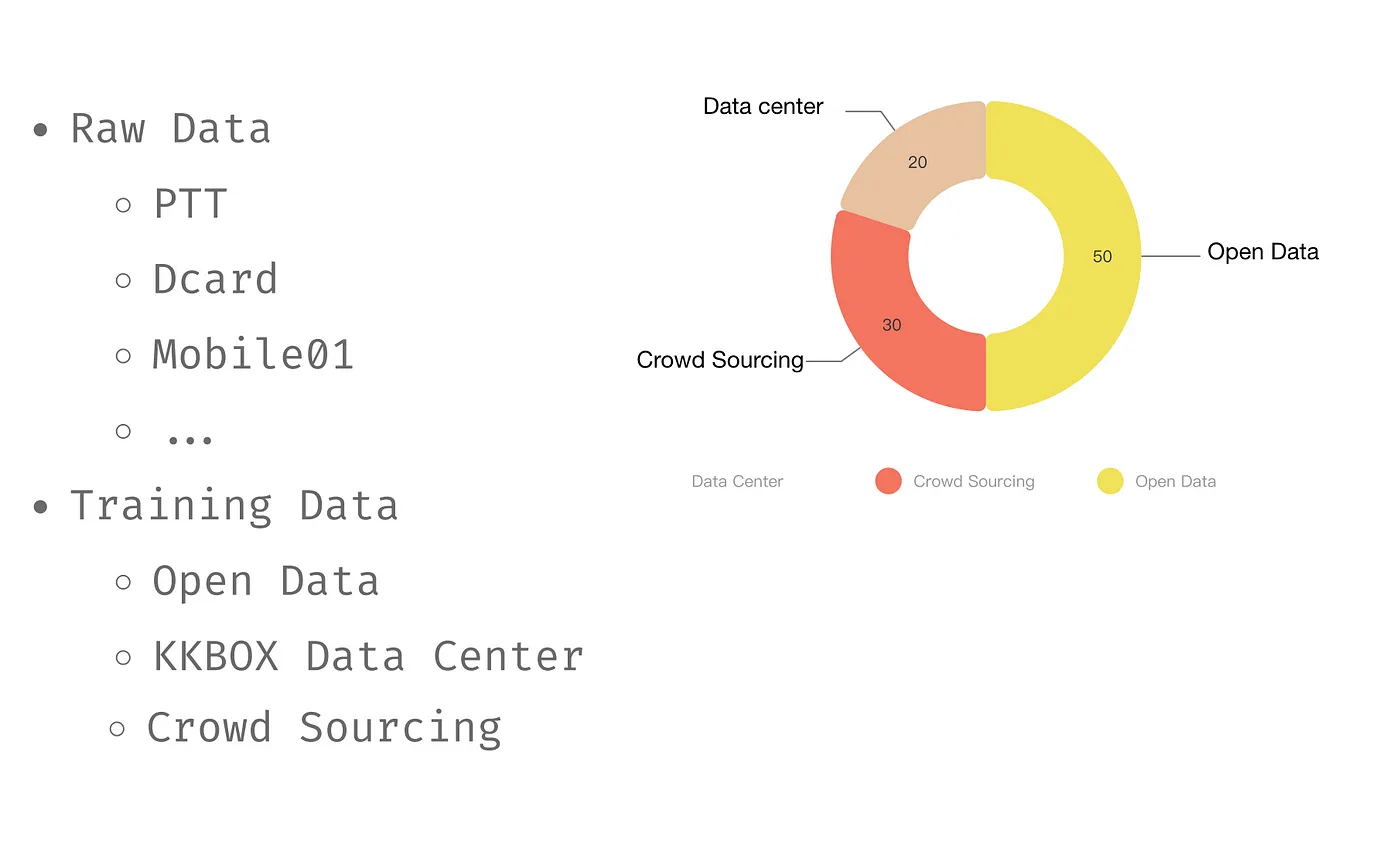
模型主要使用的 Data Source
主要來自於 Open Data、KKBOX Data Center 及 Crowd Sourcing。KKBOX Data Center 的資料是由客服所標記過的一些資料,佔 20%,Crowd Sourcing 則像是 PTT 的推文回文資料,最後有 50% 資料來自於 Open Data。
系統使用模型分享
首先先由 Embedding 開始,其實 GloVe、 Fast Text 、 ElMo 及 BERT 我們都用過,最後是留了 FastText 及 BERT。
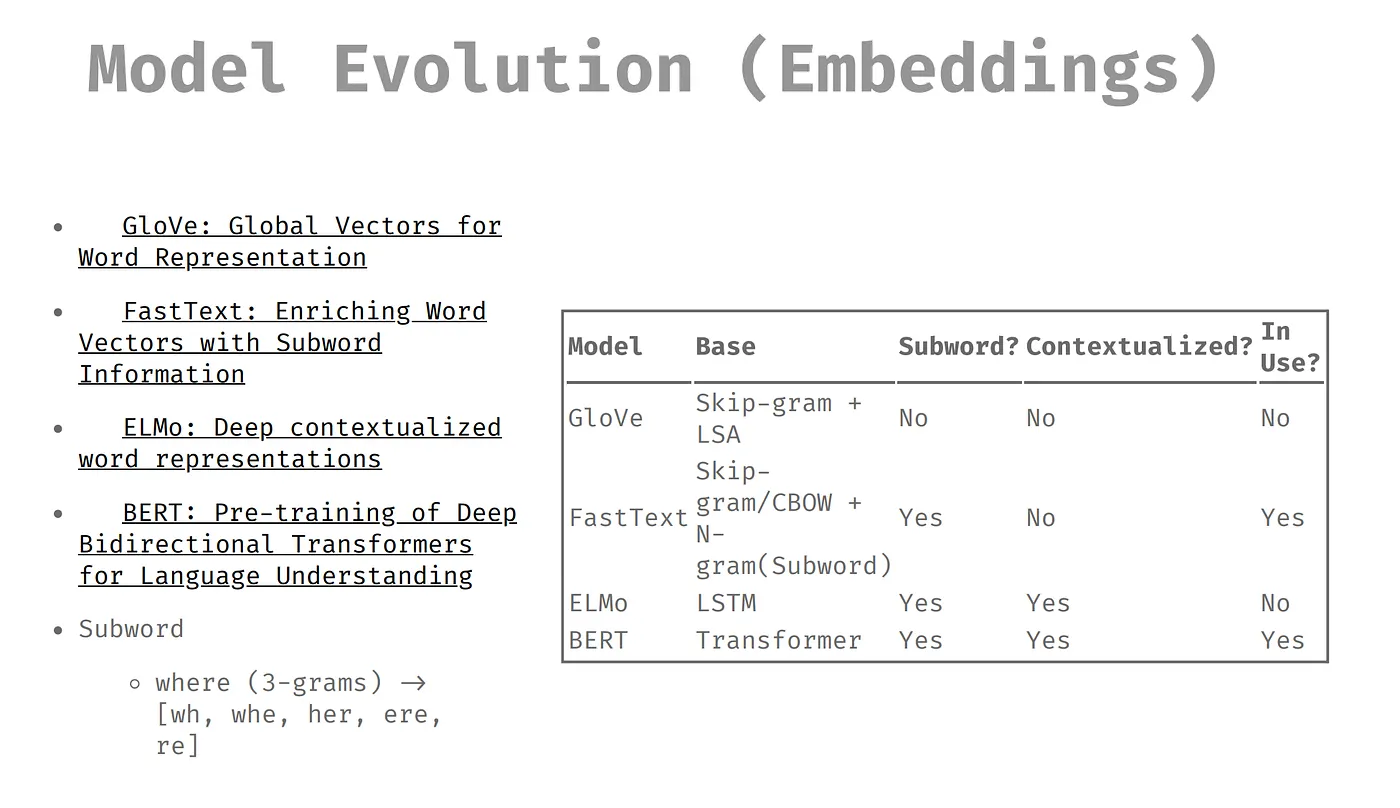
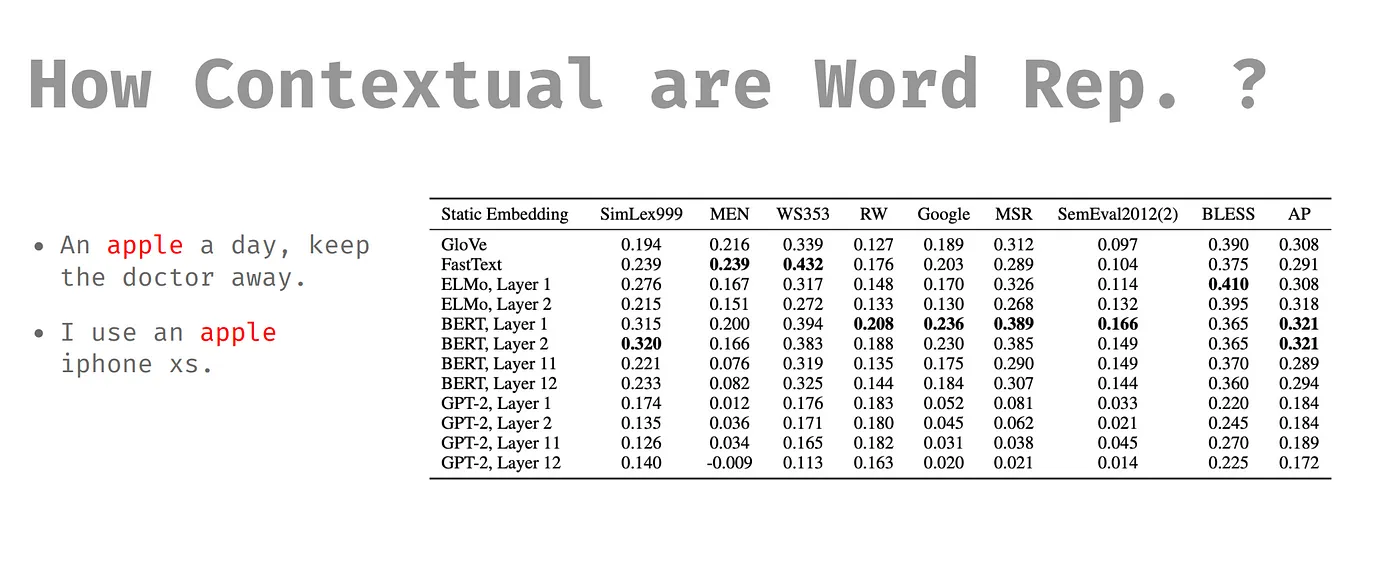
從表格中我們可以看到 GloVe 沒有 Subword ,Subword 是可以把一個字切開,即使模型遇到沒看過的字,模型可以用拆開的字去猜沒看過的字。另外,也有參考上下文的部分,什麼是參考上下文呢?一樣的字,但由上下文可以辨別字義的不同,最後以表現結果來看,是 BERT 較好。
NER 模型
前面提到的人事時地模型,這是與中央大學合作開發的,前面 2 個模型需要 Template。Template 會由人工標記,最後他們選用 BiLSTM 取代 Template。

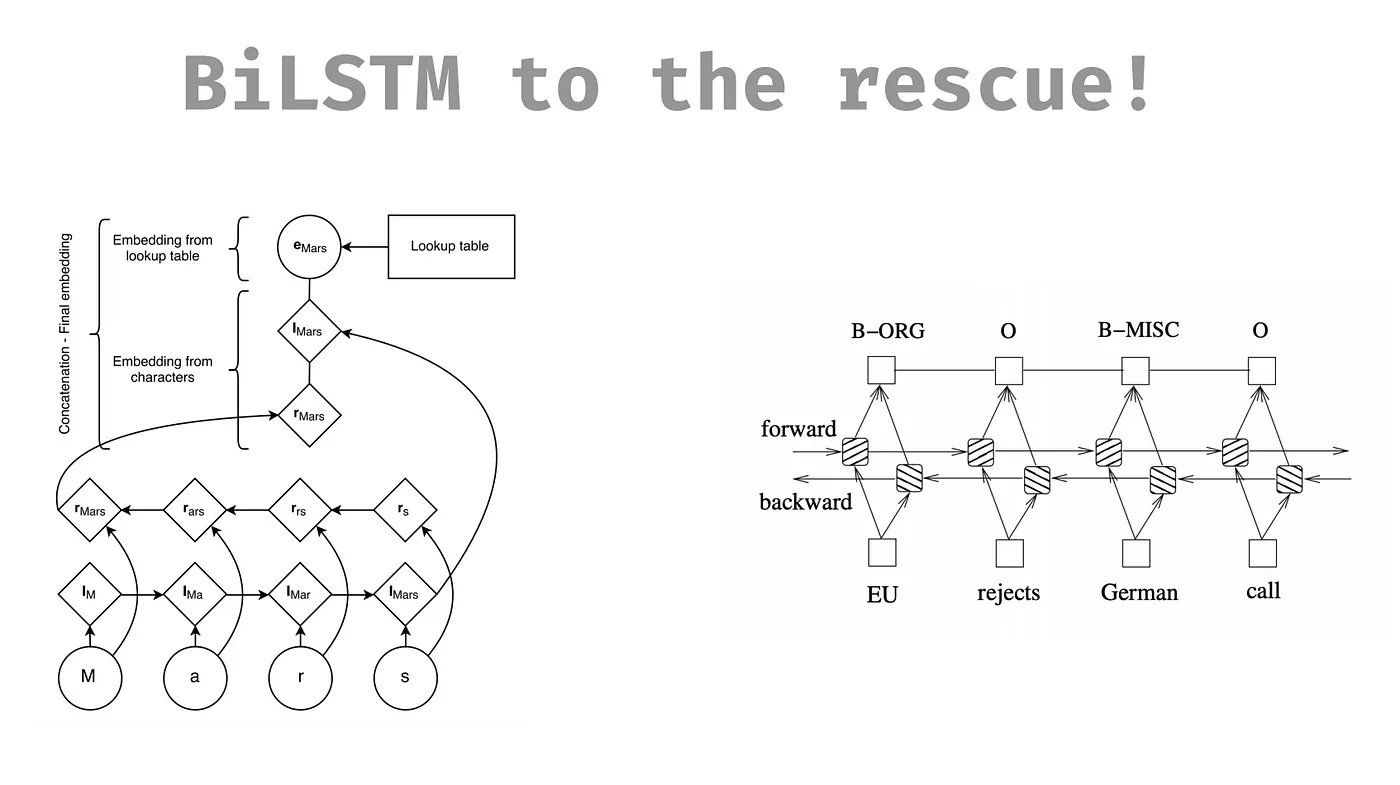
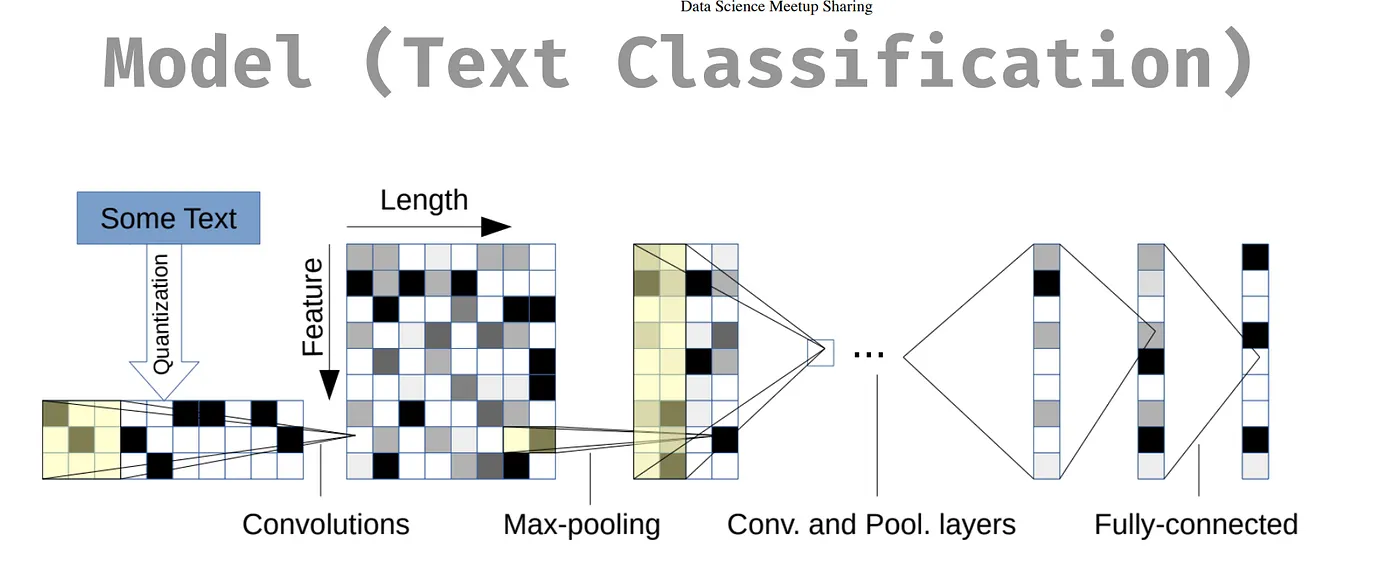
Sentiment Analysis 我們一開始用字典標記,下面兩個模型可以做到比較精細且有解釋性。
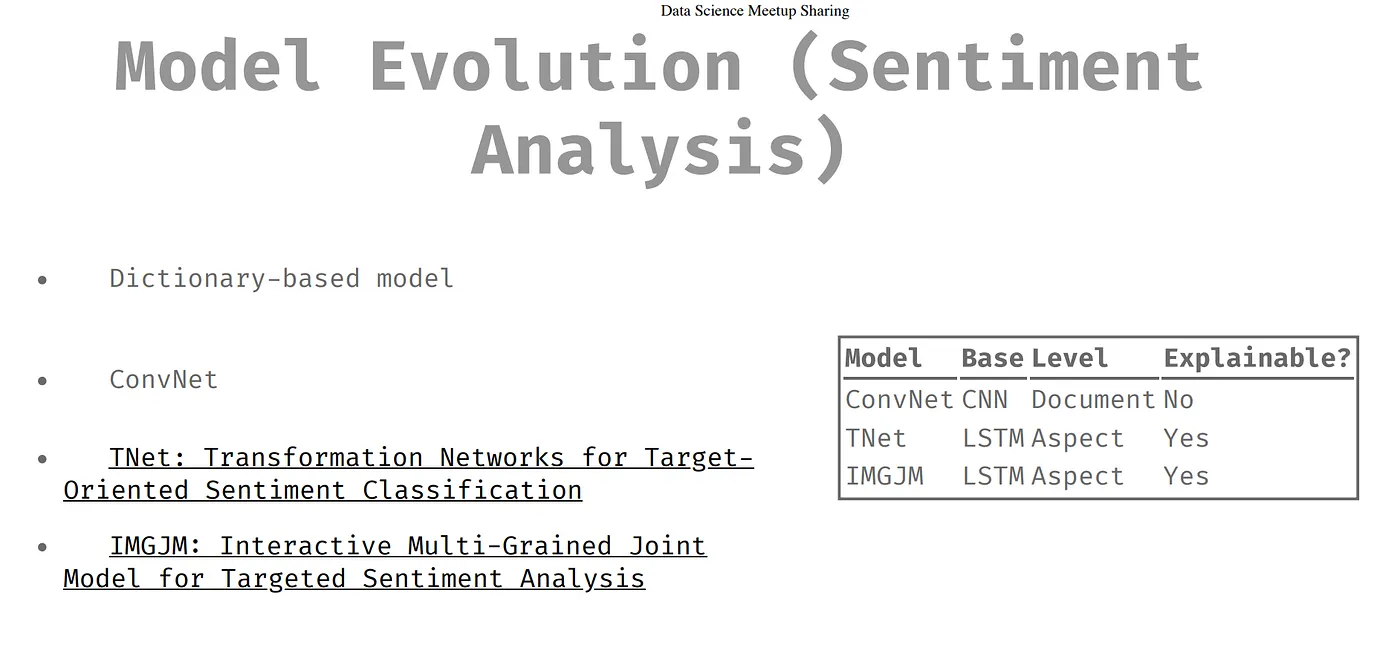
在做情緒分析會遇到什麼問題?句子中會同時存在不同部分的正負向,像是在例子中餐點是正向,而服務就是負向。在第二項 Explainable 的地方可以看出來一些用的正負向情況。也可以再使用別的模型加入偵測。

Recap
每天都有新的音樂進來,所以我們有 Automatic training,以快速更新。用 上下文去學名詞或姓氏等意思。
BERT 的速度很慢,會開很多的機器,成本高,但利用 Concurrency Framework 讓機器效果最大化。
Speed-Accuracy Trade-off ,可以用簡單模型就使用,達成目的就好。

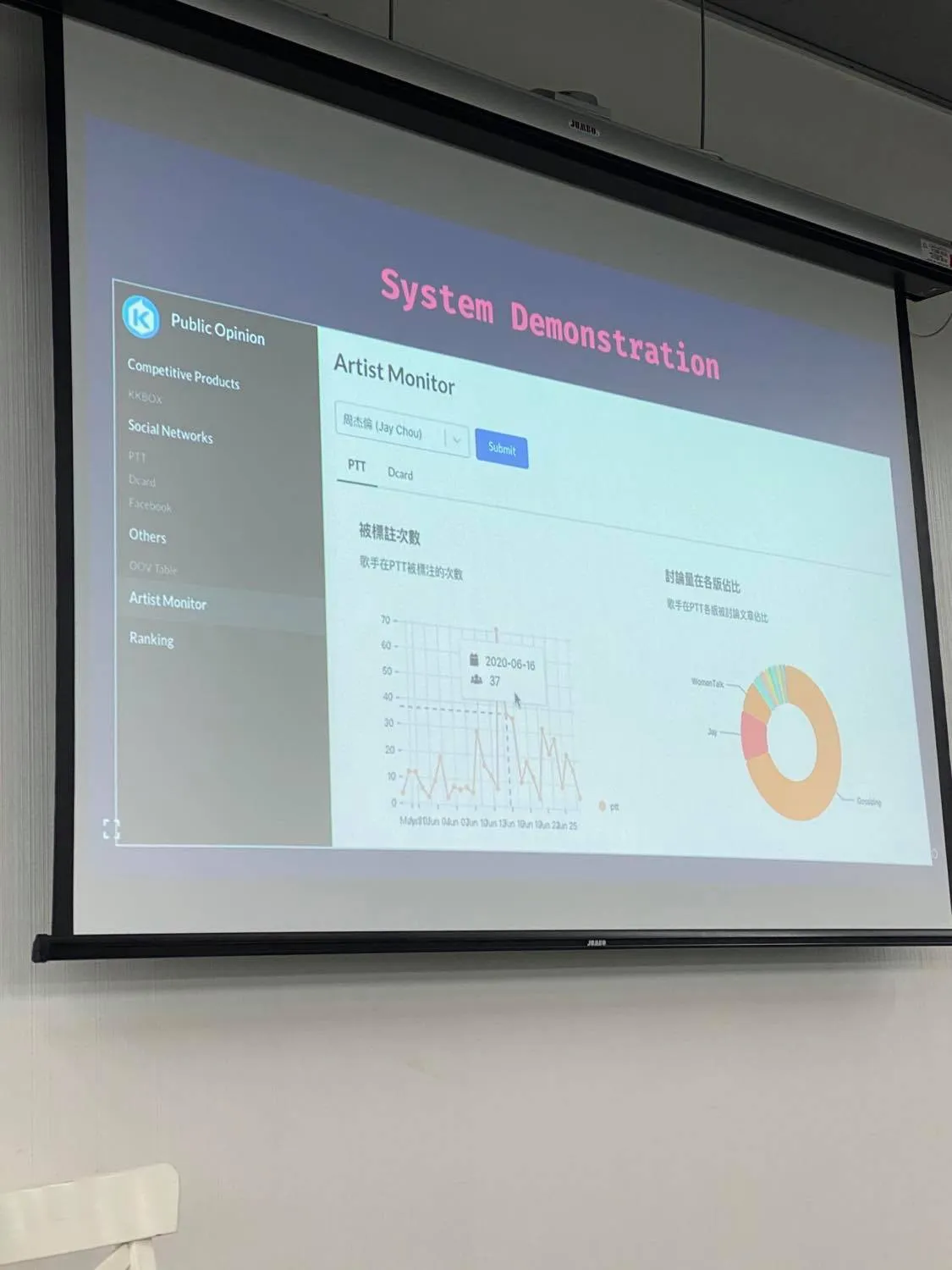
Demo
資料有 PTT 及 Dcard,裡面有被標註與討論量的相關資料,特別一提的是裡面的字其實不是人工選的,是由前面提到的 BERT 選出來的。
資源分享
Conference:
- ACL: NAACL, EMNLP, CoNLL
- NeurIPS (NIPS)
- SIGKDD
- CIKM
- IJCAI
MOOCs
- 台⼤ 李宏毅、林軒 ⽥教授 YouTube Channel
Companies
-
AllenAI (ELMo)
-
Google AI Language (BERT)
-
Google AI Brain Team (XLNet)
-
Facebook AI (FastText, RoBERTa)
-
OpenAI (GPT-2)
-
Huawei Noah’s Ark Lab (ENRIE)
-
Alibaba Damo Academic Language Technology Lab
筆記:Winnie Tsay X 維尼蔡、Wendy Hsu
校稿:HungWei Lin
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!