
統計學與機器學習模型的工程技巧 (Statistical Engineering and Machine Learning Model Engineering)
講者:超級貓 Henry|研究院自然語言機器學習組技術領導 @ Google
我們都知道 統計學 跟 機器學習 是 資料科學 的兩大基石。我們學了各種模型,希望在產品上可以使用到,然而在產品上使用經典模型時,並不是總是有辦法得到預期的效果。很多模型在實用上,需要良好的 統計環境 ,才能表現符合預期。而如何使用工程技巧創造這些環境就很重要。Henry 將帶我們了解實務上可能會遇到的問題,並且分享他是如何解決這些挑戰。
活動主辦單位: Taiwan Data Science Meetup 台灣資料科學社群
大綱:
一、介紹
二、統計學與機器學習在實務上的應用
三、統計測試(檢定)與實務上面臨的挑戰
四、Counterfactual Analysis
五、Q&A
一、介紹 (Introduction)
Henry 目前任職於 Google 的自然語言機器學習組擔任技術領導,約為 10 人 團隊。在 Google 任職8年,主要負責 YouTube 的廣告產品,平時研究多種技術供 Google 的產品做應用,也任教於 Berkeley Extension。
二、統計學與機器學習在實務上的應用
應用情境:網站運營上,衡量產品 UI 變化對使用者行為帶來的影響,如文字大小對使用者點擊的影響。

文字大小對使用者點擊的影響
假定有 10000 個 user,對於文字大小(font size)不同(10、12、14)的表現,得到資料如上圖。以 font size=10、12 來說,我們可以發現 font size =12 點擊率是比較高的,但我們能直接下結論說:font size = 12 點擊率高於 font size =10 的點擊率嗎?
Ans:透過統計測試(檢定)用數據支持我們的論點。
三、統計測試(檢定)與實務上面臨的挑戰
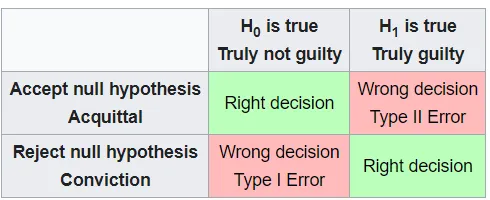
統計假說檢定 (Statistical Hypothesis Testing)
- 定義 : A statistical hypothesis is a hypothesis that is testable on the basis of observed data modeled as the realized values taken by a collection of random variables.。
以 font size 為例:
虛無假說(H0):font size 對於使用者點擊率不會造成影響。
對立假說(H1):font size 對於使用者點擊率會造成影響。
假說檢定的概念可以用無罪推定去思考,虛無假說就是沒有罪的情況,對立假說就是有罪,需要提供足夠的證據去支持對立假說 (拒絕虛無假說),反之,就是不拒絕虛無假說。
計算 p-value 就是一個提供證據的量化方法。
- p-value :假設虛無假說為真時,觀測到至少與實際觀測樣本相同極端的樣本的機率。(The p-value is the probability of obtaining test results at least as extreme as the results actually observed, under the assumption that the null hypothesis is correct.)
故當p-value threshold(= 0.05)時, 我們可以說有足夠的證據去拒絕虛無假說。[註: p-value 一般設定為 0.05,實際應用會隨著檢驗參數(例如抽樣大小)改變, 在一些狀況下可以放寬。]
常用的兩種假說檢定工具
- 卡方獨立性檢定 (Chi-Square Test for independence)
- Z檢定 (Z-test)
卡方獨立性檢定 (Chi-Square Test for independence)
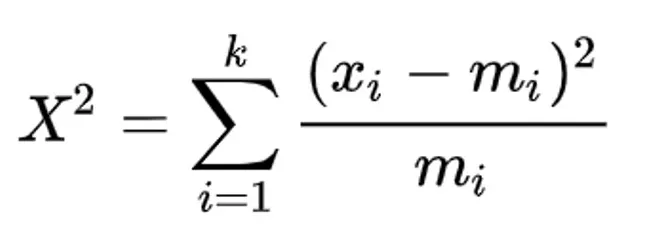
卡方統計量
- 檢定兩隨機變數是否獨立 (Can tell if two categorical random variables are related)
- H0:兩隨機變數不相關(獨立)
- H1:兩隨機變數相關(不獨立)
- 計算樣本機率是否大於 p-value threshold。(Compute P(X²((num_row-1) * (num_col -1)) > c) and compare with a p-value threshold.)
- 異常檢測(Anomaly Detection)也可以使用,去測量異常的原因(變數1)跟何者相關(變數2),如:車子溫度太高(變數1),與哪一個元件(變數2)是相關的?
Z 檢定 (Z-test)
- A Z-test is any statistical test for which the distribution of the test statistic under the null hypothesis can be approximated by a normal distribution.

Z 檢定(單變數) 各種情況以及統計量公式
- Z 檢定一般都使用雙尾檢定
- Z 檢定亦常用在兩隨機變數是否有差異
如:font size 不同下,對使用者點擊率是否產生差異。
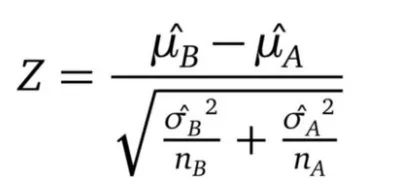
Z 檢定雙變數版本
- 根據中央極限定理 (CLT),隨機變數 Z 會服從常態分配
那麼挑戰在哪裡呢?

假說檢定 joke
- 假說檢定的過程可能會有2個問題
1. 檢定過程是有 variance 的存在,可能發生在抽樣過程等等
2. 隨機變數分配沒有那麼漂亮,可能有 noise 會影響
統計工程 (statistical engineering) 問題主要透過 reduce variance 就可以解決大部分的問題。
應用例子:投資常常推薦買 index fund 就是因為其 variance 小。
- 我們可以透過 增加樣本數 去 reduce variance。
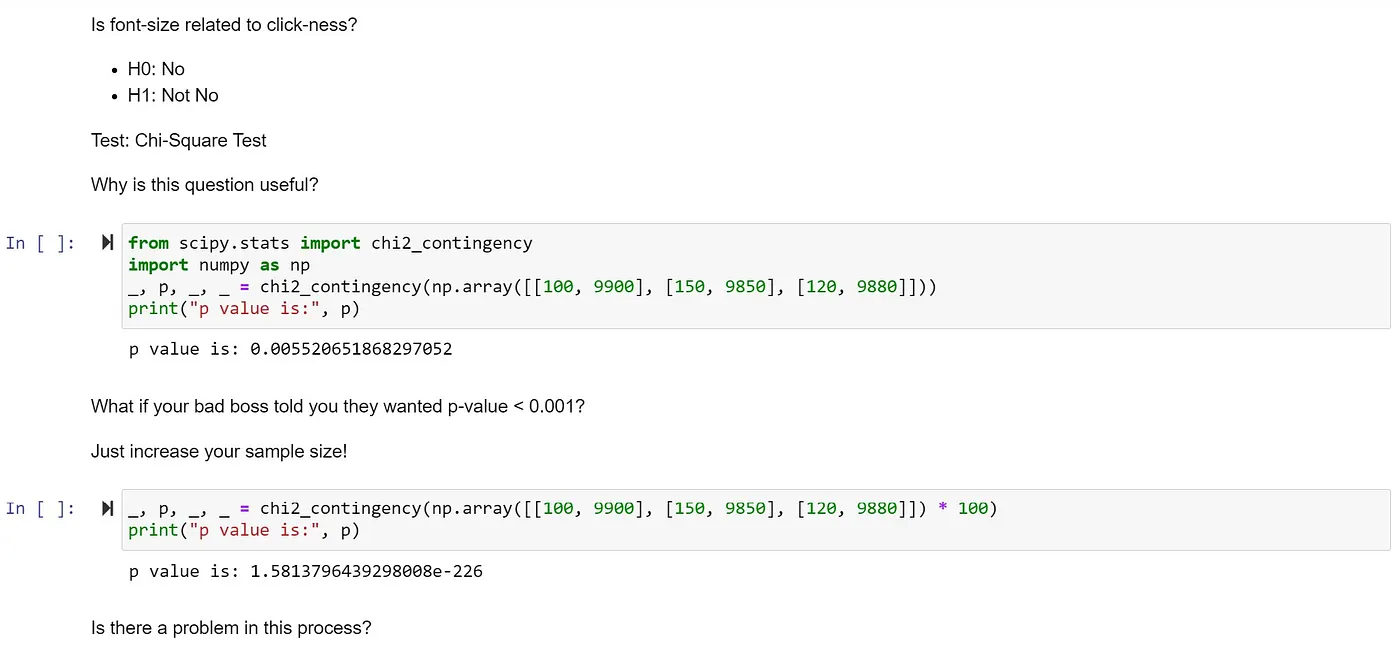
增加樣本數去 reduce variance
但是也產生了新的問題, noise 也跟著樣本數同時被放大 。(下圖)

small bias crash the process
可以發現當樣本數很大的情況下,p-value 變得很小,noise 力量就跟著被放大,造成了拒絕了虛無假設(H0)。
Bucketing
透過 Bucketing 技巧可以降低 noise:透過將 近似區間的數字用相同數字取代 。
如下圖,將98透過轉換變成100。
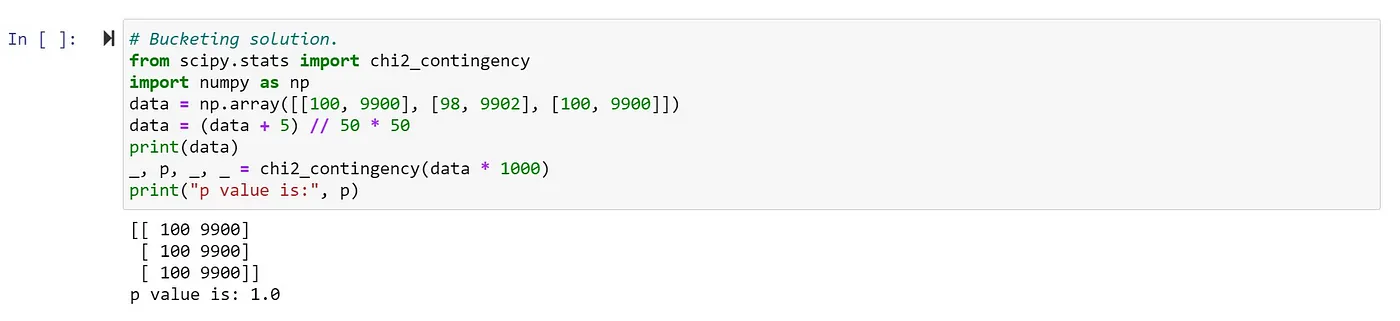
Bucketing solution
四、Counterfactual Analysis
相關不是因果
- Type 1:A 和 B 相關,但其實 A 與 B 沒有因果關係,是有 C 去同時影響了 A 與 B,讓我們誤以為 A 和 B 是因果關係。
- Type 2:coincidental events
Type 1
- 例子:有養寵物(A)的人比較長壽(B)
也許實際上是越有錢©的人會去養寵物,所以應該是越有錢的人越長壽。 - 我們真正要問的是,那些沒有養寵物的人,在養了寵物之後,會變得更長壽嗎?(counterfactual)
- 但很顯然,這是 不能實行的實驗 ,但我們可以透過 近似 的方法去測量。
→ double-blind experiments (醫學上常用)
例子:一群病患罹患相同疾病,醫生給予一些人安慰劑(placebo),給與另一些人藥劑,但醫生也不知道哪些是安慰劑、哪些是藥劑,造成醫生與病患兩方都不知道獲取的是藥劑還是安慰劑。
A/B testing 是一個很好地近似 double-blind experiments 的方法。
但也有一些問題:
- 使用者會觀察到其正在實驗當中 (Users can observe the existence of the experiment)
如何去解決 (How to solve such problems?)
五、Q&A 精選
Q1:請問數學/統計學相關能力都是如何培養的?
- MIT 有一些 open course,裡面的資源都很棒,可以去學習。
Q2:Kaggle 競賽的成績對於求職上有幫助嗎?
- 有,但是 Kaggle 上為了追求成績可能會去做一些不常見的trick,但在工作上,其實更要求基礎技術的熟練,如神經網路、誤差反向傳遞等等。所以我們自己面試上,也是看重對於基本的爛熟以及肯學習新的觀念,因為機器學習日新月異,學習能力就顯得更重要。
Q3:請問要應徵 Google 機器學習/深度學習相關的職位,也需要刷 Leetcode 嗎?
- 需要,一般來說,做機器學習相關的職位對 Leetcode 的要求是比較低一些,但也通常會有 1-2 題,只要能解出最佳解就好。且如果是比較高階的職位,就會著重於其他部分。
Q4:想請問就您的了解,美國的就業市場現況,資料科學領域是否僧多粥少?有哪些能力在公司上是比較重視的,統計、數學、coding、Product sense? 謝謝
- 其實真正 qualified 的人才還是很難找,junior 等級可能的確競爭比較激烈。
- 很重要的技能是,能夠將統計、數學真正使用在產品上,可以使產品、工作的 process 變得很快,可以透過數據說服別人為什麼要做這個決定。 有Product sense的資料科學家很重要 ,但非常少。
- 量化能力也是一個很重要的能力 ,也是後期與別人顯現差別的關鍵之一。
Q5:沒有數學/統計背景,在深度學習之前,有沒有什麼方式可以檢測自己適不適合?
- 我自己都跟學生說,有沒有什麼產品或者事情讓你感到充滿熱情,大部分人都有接觸一些數學/統計,如果你對這方面沒有太大的興趣,至少要在其他地方有熱情,如產品、產業等等。
- 這是一個長期的過程,你要做到有一定成績,需要渡過前面好一陣子的摸索、學習,如果沒有熱情可能會有點辛苦。
筆手:Aaron Yang
校稿:超級貓 Henry
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!