
講者:甘志雯( Wendy Kan)|ML engineer @ Google Ads | ex Head of DS @ Kaggle
Building a data science team and ML systems at Kaggle
建立資料科學團隊
隨著資料科學在各領域的開發、應用持續升溫,建立專業分工的團隊是必經之路。資料科學團隊的建立會面臨著不一樣的挑戰,讓我們跟著 Wendy 了解其在 Kaggle 面臨的挑戰。
活動主辦單位: Taiwan Data Science Meetup 台灣資料科學社群
大綱:
一、介紹 (Introduction)
二、資料基礎設施 (Data infrastructure)
三、分析系統 (Analytics systems)
四、機器學習 (Machine learning)
五、Q&A
一、介紹 (Introduction)
講者: Wendy Kan
講者介紹:
在 生醫工程 跟 醫學ML界 打滾幾年後,Wendy 在 Kaggle 做了四年的資料科學家,主要負責設計ML比賽。過去兩年間,Wendy 在 Kaggle 成立了一個小Data team。Wendy 將會分享從零開始成立一個小Data team遇到的挑戰。Wendy 目前已經離開 Kaggle 加入了Google Ads AI team,不過仍然與Wendy待了六年的 Kaggle 有友好的合作關係。
二、資料基礎設施 (Data infrastructure)
挑戰:散落在各處的資料 (Data everywhere)
- 原因
- Kaggle的資料分析團隊在一開始,資料基礎設施不佳,資料來源非常複雜,發現許多人在做相同的系統建立上(如join不同來源的資料),資料成長得非常快,會有發生crash的風險。 - 不同的資料來源分析過程(原先)
- Back End Analytics(MSSQL DB): 從資料庫透過SQL Explorer / Local(or GCP) MSSQL connector 去取得資料轉換成kaggle Dataset並在kernels中做分析。
- Front End Analytics: 從前端網頁埋點觀察使用者行為收集的資料庫,透過BigQuery / Data Studio取得、使用資料去做分析。
- Google Analytics(較少用,忽略) - 透過ETL整合不同的資料來源
- 開發時程:
- 2個月設計
- 3個月實作
- 2個月資料隱私review - 系統架構:
Data Source (Back End Analytics/Front End Analytics/Google Analytics) → ETL(v1: Airflow, v2: Custom) → Data Warehouse → 應用場域 (kaggle note books/BigQuery/Dashboard/Kaggle Datasets) - 成效:
- 公司內部的任何人都可以透過Data Warehouse簡易地取得想獲取的資料,改善了原先大家重複地從不同資料源整理合併地過程。
- 甚至可以透過簡單的BigQuery UI直接獲取資料。
4. Lessons learned
- 基礎設施是資料科學團隊的基礎
- Hacking : 可以去創建一次性的解法,但要設立停損點去建立基礎設施,如: 看到大家不斷在做相同的事情(整合資料)。
- Scale : 越早考慮越好,資料會成長得比想像中快,若設計不好,可能會產生crash風險。
- Vision : 用最小的努力去達到最大的成效,因此,建立的系統優先解決大多數人最主要的痛點。 - **避免客製化軟體,善用現成工具
** 尤其在小公司,維護的時間成本特別高,不論是處理各資料庫的交互等等問題,若可以使用現有穩定的工具,就去使用。 **
**- 使用開源工具或者是付費的雲端工具。
- 試著不要客製化data connectors 以及 ETL系統。
- 維護客製化的軟體非常痛苦,尤其是小公司。
三、分析系統 (Analytics systems)
挑戰:基礎設施建立之後,太多分析需求需要處理,如何制定優先順序以及解決方案。
- 原因
- 不同部門的需求眾多如: 有多少TensorFlow vs PyTorch個別使用者? 有多少使用者在Fortune500大公司? 可以建立Dashboard嗎? 可以建立一個分析並產出報表嗎?
- 在眾多需求之下,資料分析部門需要排列優先順序以及必要性,對於公司的文化也開始真正的轉變。 - 分析優先 (Analytics first)
分析的CP值非常高,雖然我們都想要做ML,但有的時候分析就足夠去解決大部分的問題。
- Drive value, deliver insights, build intuition
a. Superpower: ****
從資料中取得動見,驅動/支持商業決策。
b. Build data intuition for ML definition: ****
因為許多做ML的人員其實專注於技術本身,但並沒有妥善地結合商業價值,許多的專案最後是沒有產生impact,因此從分析中建立對商業問題、價值的理解是必不可少的。
**- Determine centralized or distributed Data Science team
**a. Centralized:
將資料科學團隊壯大,專門去處理各部門的分析問題。
b. Distributed:
透過諮詢、分享,如給一個簡單的例子讓部門的人學習,將分析的文化植入各部門,讓各部門的人也可以有分析能力,也是 Wendy 在 Kaggle 時採用的方法。 **
**
- Give people freedom to choose tools
a. Can always consolidate later:
讓大家多去使用系統為優先,先建立起data-driven的文化。
- Analytics or ML?
a. Be patient. ML system is hard! ML system takes time to define, build and to tune
b. Deliver analytics results quickly
c. In the meantime, you lay the groundwork for ML (usually infrastructure is shared)
3. 分析系統 (Analytics systems)
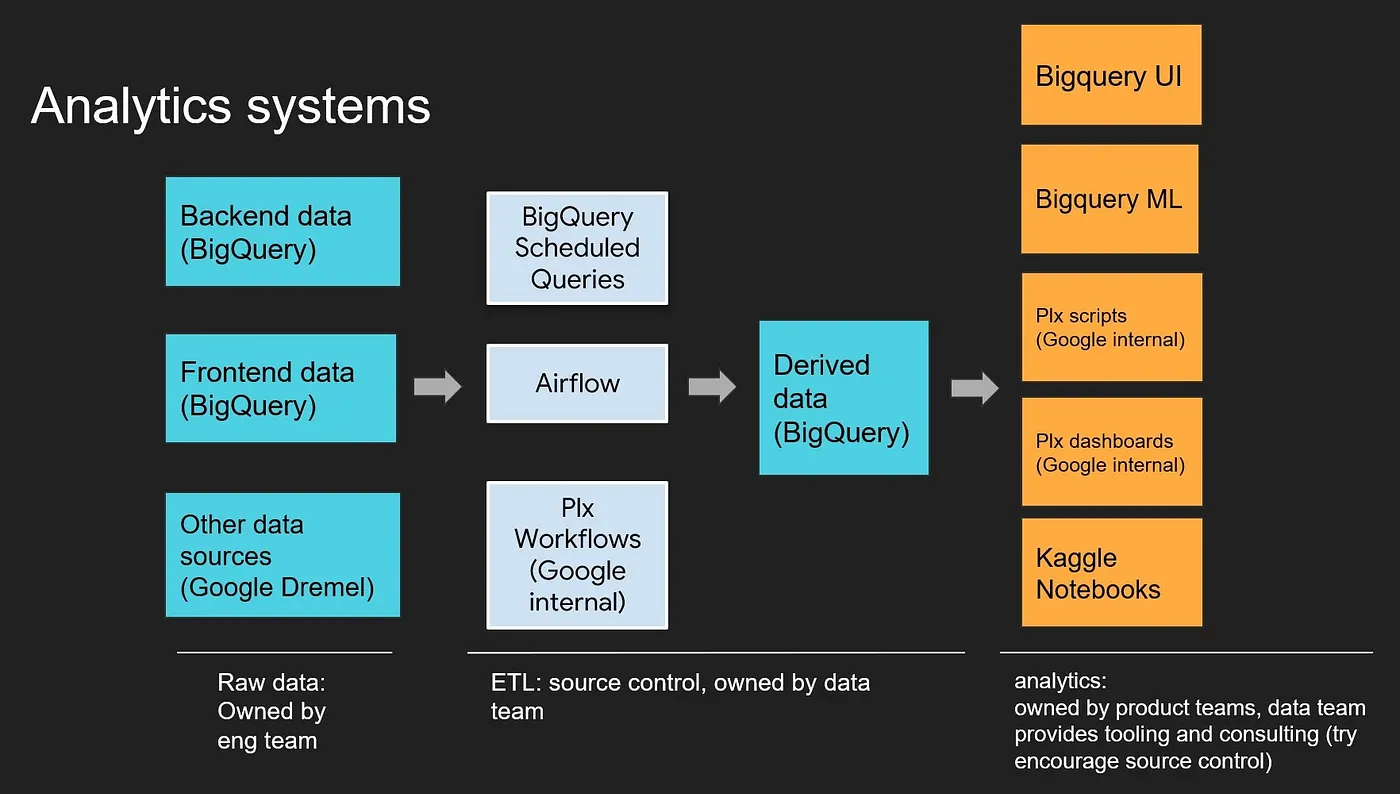
Analytics systems
4. 例子 (A workflow example)
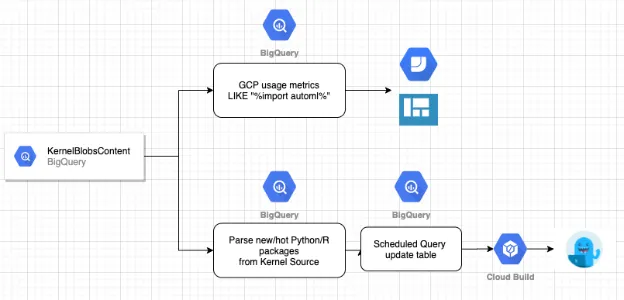
Workflow example
- 在建立了基礎設施之後,原先需要專門一個工程師做的分析工作(更新Kaggle 最常用的package到kernel上),可以透過 BigQuery 去自動在雲端運行,節省了以往人工的部分。
四、機器學習 (Machine learning)
挑戰:一個問題通常都有許多解決方法,你需要去找到證據去支持現有的方法不夠好,需要去建立ML方法,在途中遇到的挑戰。
- 為什麼不使用heuristics (Why don’t we use heuristics?)
- 在做ML的時候,一定會有很多人問到為什麼需要ML?為什麼不等一段時間得到真實資料後去做統計量當做value?(heuristics)
- 或者為什麼要選擇建立一個需要時時維護、更新以及監控的ML系統,需要大量的資料標籤以及其他工程? - Lessons learned
- It’s okay to use heuristics:
a. 首先一定要考慮ML的必要性,如果沒有資料就先去取得資料或者考慮取得的成本與效益是否合理。
b. 先用heuristics方法去解決問題,看結果是否已經足夠好了,再決定是否繼續。
**- 需要做一些實驗確認需要ML去解決問題 (It takes some experiment to show you really do need ML):
** a. 先做 PoC 去嘗試,確保有是潛力的。
b. 保持 PoC 簡單,不論是演算法或者是系統。
c. 為了速度、效能以及使用者體驗,先用現存的ML服務去建構PoC是完全沒問題的。可以在確定有潛力之後,再建立更客製化的服務。
**
(補: 可以透過 參加比賽(kaggle) 訓練快速prototype的能力)
- 如何去說服公司需要ML (How to convince people?)
**a. 從領導者/決策者的觀點出發去思考。
b. 提出細節的分析,透過成本/收益的資料分析佐證來說服投資是值得的。
- 找到適合的題目去預測 (Picking a “thing” to predict)
- 在找尋10餘個題目之後,成功實現2個
- 其中之一是 notebook的品質預測 _
_a. notebook品質對於排序/得分/過濾等等工作是有幫助的。
b. 對多個部門都有益,可以在不同的部門中分享,因此決定此題目。 _
_ ** - 提出正確答案是非常難的(下列為途中遇到的難題、挑戰)** _
_ a. notebook品質是非常主觀的。
b. 透過使用者表現尋找替代標準。
c. 花費更多的時間在ground truth定義上, 而不是模型建立。
d. 先前建立的資料分析結果就在此處幫助很大。
e. 不斷與 stakeholders (如產品決策者)確認目前假設是否正確。
- **成功指標 (Success metrics)
- 確認stakeholders
** a. 誰會去使用預測結果/會如何使用。
b. 誰會投資我的模型。 **
- 提出商業/產品指標
** a. 商業指標與ML指標有可能不一樣。
b. ML指標以數學上合理為優先(如PR-AUC, Accuracy等等)
c. 盡量使商業指標與數學指標方向一致,但這不容易,如: 有時候商業指標只專注於前10%資料的準確度。 **
- 與stakeholders設定模型表現目標
** 例: 如果模型表現指標達到x%, 將會替公司省下 $Y, 就launch模型。
**
- 如果需要重新定義模型成功指標,不斷溝通確保雙方認知一致。**
BigQueryML使用經驗 (Experience with BigQueryML)
- 簡單易用
- Data wrangling 在SQL內完成
- 模型在SQL內建立完成
- 疊代模型快速
- 與TF hub相容,能夠從前者import TF 模型
AutoML使用經驗 (Experience with AutoML)
- 簡單易用
- 節省開發時間
- 特徵篩選: 特徵效果快速檢驗
- 便宜: 3小時 $ 5
- 最後沒有用在生產環境,但如果要在生產環境應不困難
將ML導入生產環境中 (Putting it in production)
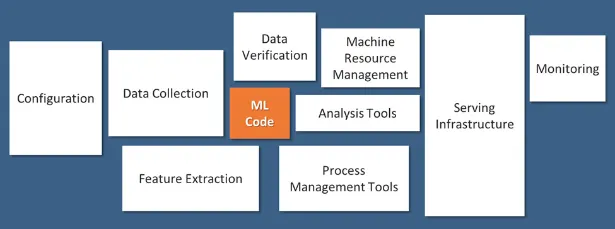
system structure
保持系統簡單,使得維護容易,第一次嘗試可以忽略部分components。
-
資料同步
-
特徵
-
訓練
-
監控
-
推論/預測
-
架構 (What we ended up with)

Our choice, Kaggle
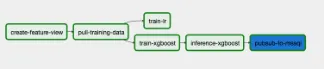
Training
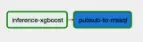
Inference
結論 (Conclusions)
- 對比大公司,小公司面臨的挑戰是很不一樣的。
- 即便是Kaggle這種以資料科學為主的公司,要說服去做ML專案也是不容易的,因為其成本/資料要求高。
- 藉由耐心、經驗以及細心驗證,可以在成本與收益之間找到平衡。
五、Q&A 精選
Q1:您好!謝謝分享!資料科學團隊通常都有許多目標,就我的經驗,我們公司的資料科學家沒有接觸到這塊,想請問是因為團隊大小的關係造成需要去做基礎設施這一塊嗎 ?
- 根據公司而不太一樣,因為我們公司只有50個人,人手很緊,純軟體工程師就是專注在Web上面,沒有軟體工程師分到資料分析團隊中。又我本身是一半的軟體工程師,當下的需求需要基礎設施,我就跳下來做了。但其實根據情況不一,如果衡量自己這方面的能力不足,就去跟公司要求援助,如果有能力且有需要就下去做。
Q2:您好!好奇平常 Wendy 會遇到什麼樣的分析問題 ? 又是如何訓練分析能力的 ?
- 比如說: 1. 用戶都是大公司還是小公司,2. 用戶是不是學生,這些資料可能沒有強制要求,我們必須透分析去找出答案。首先,我會去詢問 為什麼要問這個問題 , 確認問題的重要性(business critical) 再決定要不要做。如果要做且容易,就馬上給答案。但有一些問題是比較困難的,可能在解決問題的途中,延伸更多問題需要先處理,才能達到答案。這是一個很tricky的問題,因為小公司人手不足,有時候分析沒辦法做得很深。
Q3:Wendy 您好!前面有提到團隊是centered還是distributed,如果有一些sales representatives是不會寫SQL的,有些是會寫的,有些問題是持續性的,有些是一次性的,您會怎麼去排優先順序 ?
- 這個問題很好,我也花了很多時間去找到平衡,request太多了。以前我是request來我就做,但後面調整到一個quarter我會安排1/3的時間在做這些分析。第一步是 篩選 ,如果跟商業、部門間的影響力不強,就剔除。第二步則是 訓練 ,當時我們團隊的人都是可以訓練的,因此我有部分是透過教學,給一些簡單例子去訓練他們。第三步就是給contract data scientist去做,但通常都要做dashboard,這非常花時間,所以要選擇好的題目。
Q4:想請問「非工程類的博士學位」(雖然研究有應用很多ML與資料分析)是否有助於DS領域的職涯發展。會不會沒有博士學位很容易碰到天花板爬不上去?
- I don’t think degree matters that much after a few years of experience
Q5:請問 Kaggle 透過前後端資料分析,因此得到什麼觀點來改善服務呢?
- A lot of product decisions such as whether users show interest in certain features
Q6:Data team人數不多,而且operation有一定程度loading的情況下,想專注做研發(嘗試新的演算法,或多種modeling方式同時做model selection…etc),人力上如何調配? 是否該把operation跟R &D在組內加以區分比較可以專注?
- Very good question. Yes, eventually you should split the ops (one off analytics, maintaining dashboards, pipelines) and R&D. Not necessarily between people, but maybe focus on different things in sprint, or have an on-call rotation on ops.
筆手:Aaron Yang
校稿:甘志雯( Wendy Kan)
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!