
從生物學家到金融服務業機器學習工程師:一段走向華爾街的旅程
Chia-Ta Tsai | Associate Director in Machine Learning @Moody’s Analytics

活動主辦單位:Taiwan Data Science Meetup 台灣資料科學社群
摘要
本次演講將分享一位對資料科學和機器學習充滿熱情講者的職涯經歷。他的旅程始於台灣攻讀計算生物學博士學位,隨後在紐約市工作數年。其中經歷了多次自主學習和轉型後,他近年在金融服務業擔任機器學習工程師。 內容關注在分享持續學習、適應性和參與多樣化計畫在橫跨金融服務與科技行業中的經驗與反思 。此外,在演講的剩餘時間中,講者將探討一些近來自然語言處理和人工智慧在金融服務業的應用,以及在新興監管科技領域中利用大數據與機器學習的發展。
大綱
- 講者介紹
- 講者的職涯旅程
- 4種作法 — 從無經驗到有經驗
- 金融產業中的資料科學應用
- 精選QA
講者介紹
Chia-Ta Tsai 目前在Moody’s服務接近兩年的時間。目前在旗下的穆迪分析(Moody’s Analytics)的機器學習工程副總監(Associate Director — Machine Learning Engineer) ,迄今旅美在業界有4年多的工作經驗,專案參與內容橫跨機器學習、資料科學、軟體工程,在進入業界工作之前主修生物科技,並曾取得計算生物學博士候選人資格。

講者自介 — 圖片來源 — 講者投影片 [1]
Moody’s 在做什麼
Moody’s是美國一間整合性風險評估企業,主要產品都和風險評估有關,像是提供產業資料、產業報告,以及市場解決方案。旗下主要有兩間子公司:
- Moody’s Investor Service — 主要產品是提供信用評級,也是公司主要收入來源。在財經新聞上常見的債信評級報導皆屬此類。
- Moody’s Analytics — 提供財務分析報告、財務分析軟體、財務分析服務,聚焦在風險管理領域。
講者在 Moody’s 的工作內容
講者 Moody’s Analytics 任職期間主要在兩個不同的營運部門服務。一開始先在 Predictive Analytics 部門下的ML team,該部門主要是透過 AI /ML 來提供預測性分析的產品,後來因機遇轉往了 Know Your Customer — Know Your Business (KYC-KYB) 營運部門服務,在該集團中, Data Science 的職能會散在各個不同的部門中,講者所在的則是產品策略部。
日常工作內容
- 根據產品專案的需求,建立 PoC與MVP 。主要會使用大數據框架PySpark,或是 Machine Learning、Transformer 模型、Micro Service 以及 ETL pipelines 等技術來展現實用性與可行性。
- 協作上內部需要與資料團隊(包括資料工程師、資料分析師和資料科學家)進行密切合作。同時,也需要與負責產品策略的產品經理與分析師,以及工程開發團隊(前端、後端、UI/UX設計師)進行跨部門的合作。
- 在橫向溝通方面,機器學習工程師需要向產品或專案團隊明確解釋機器學習和人工智慧可以實現的範疇與功能。而在團隊內部的溝通上,他們則會集中於分享已完成的專案經驗,並帶領資淺組員實踐業界Best Practice,以持續提升團隊的技術能力和效率。

講者工作日常 — 圖片來源 — 講者投影片 [2]
講者的職涯旅程
兩種生物學家
在講者還在學校的時代,生物學家主要有涇渭分明的兩種生涯路線:
- 實驗生物學家:在實驗室使用生物學技術,如細胞培養、基因操縱和蛋白質分析,製備各種樣品,實際接觸研究樣品,對生物進行各種實驗,像是病毒、細菌、細胞到各級生物或者人體。進行研究工作需要穿著實驗服,通常這種研究工作稱為 Wet lab。
- 計算生物學家:主要進行透過電腦進行計算或模擬,不涉及實際的化學品和生物樣本。利用計算和理論方法,執行數學建模、數據分析,通常提出預測後常需要真實實驗數據互相印證。通常這種研究工作稱為 Dry lab。

兩種生物學家 — 圖片來源 — 講者投影片 [3]
在大學求學期間,講者發現自己的興趣並不適合成為實驗生物學家,於是決定向計算生物學發展,修習許多與資訊科學相關的課程,並進行計算生物學相關的專題研究與攻讀研究所。然而如今實驗生物學與計算生物學的界線逐漸模糊。例如,講者的同學雖然是實驗生物學家,但也需要學習使用電腦計算分析工具來進行研究(並且要使用 docker 來佈署)。而計算生物學家現在的工作更多地集中在創建新的計算方法和工具上。
另外,講者也有的學長姊在獲得博士學位後,曾在藥廠擔任實驗生物學家。後來,他們通過線上課程進修,轉職成為資料科學家。之後他們在職位晉升方面的速度比之前擔任實驗生物學家時更快。
從學界到業界
進行從計算生物學家轉職進業界作為機器學習工程師的差距分析(Gap Analysis) ?
雖然在求學與學術研究時,講者學習了一些計算理論方法和撰寫程式語言(主要是C++),並已在研究中使用機器學習(ML)模型,但主要應用於較小的,由實驗產生的資料集進行分析。然而在產業界,講者面臨需要進行多方面的轉變。
首先,主流使用的程式語言 Python 和 Java 。其次,在資料處理方面,需具備更高級的技能,例如各種複雜的特徵工程以及掌握大數據運算框架(如Spark )。最後,軟體工程技能的掌握也變得至關重要,例如使用 Git 進行工程師之間的協作、熟悉雲端平台以及掌握 CI/CD 佈署技能。

實驗室與業界的工作內容差異 — 圖片來源 — 講者投影片 [4]
在講者的職業生涯中,他在多份工作中積累了不同的技能,並借助之前工作所學的新技能跳槽到新的機會。離開學校後,他的第一份產業界工作是在Preseed 階段的新創公司擔任創始團隊成員。在這裡,他累積了大量數據科學和機器學習的實務經驗,學會了端到端建構資料和機器學習管線,編寫(production grade)的程式碼以及使用CI工具協作。
之後,在承攬微軟的合約工作期間,他參與了建構多語言深度學習個人化推薦系統的團隊合作計畫。在過程中,學到了更大規模上的軟體工程和大數據處理知識與經驗。同時,他還接觸到了使用GPU進行平行計算的Transformer應用,獲得了自然語言處理(NLP)的第一手經驗。
憑藉這些累積的經驗,講者首先以 NLP Machine Learning Engineer 的約聘身分加入了Moody’s,並在經過累積數個月的貢獻後獲邀改聘為全職的資深員工。
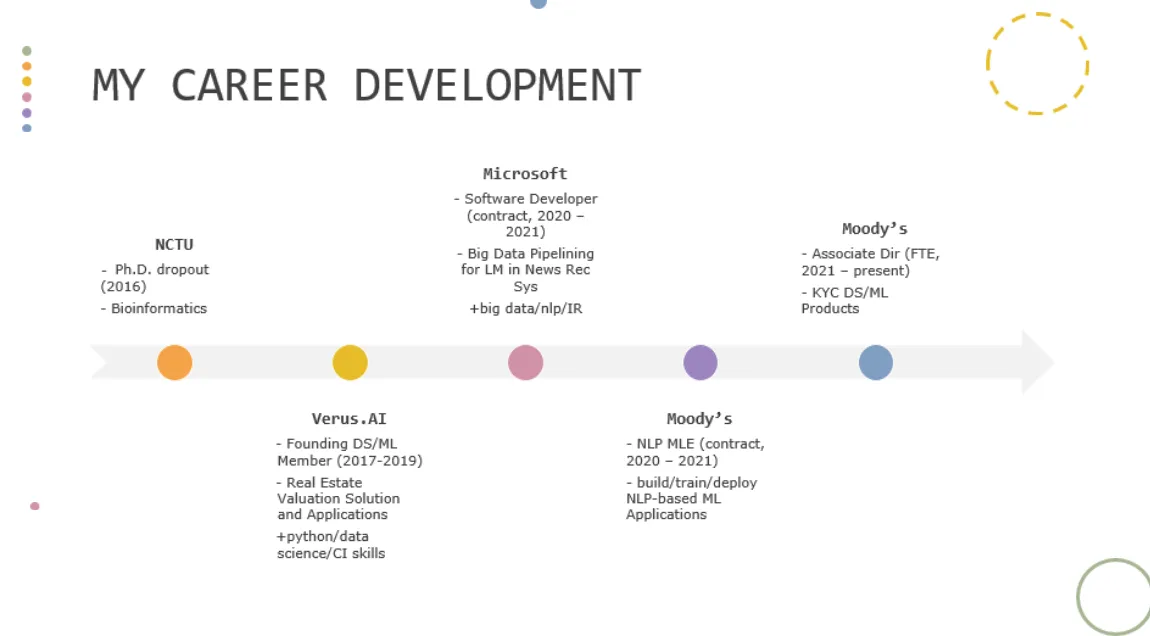
講者的職涯發展路徑 — 圖片來源 — 講者投影片 [5]
4種作法 — 從無經驗到有經驗
如果在沒有相關學經歷的情況下想要以替代的方式進進入金融服業工作,講者利用詢問 ChatGPT 所得到的框架,有系統地將自身的經驗對照驗證。以下是 ChatGPT 提供的指引,可以從以下四點切入 :
- 考慮替代職位(Consider Alternative Roles)
- 取得相關證照(Pursue Relevant Certifications)
- 獲取相關經驗(Gain Relevant Experience)
- 社交聯繫(Networking)
以下依序搭配講者經驗說明。

從無經驗到有經驗,ChatGPT Guideline — 圖片來源 — 講者投影片 [6]
Consider Alternative Roles
雖然每個人皆會有自己夢想中的工作,但無法一步達成時,可以考慮用不同的職位逐步累積相關經驗。在講者的過去經驗中,對於不同的職務類型也有不同的體悟,例如小公司和大公司的差異,以及顧問和全職員工的比較。
小公司 vs 大公司
公司的規模決定了對人才的需求類型。在新創公司,通常需要具備多方面的技能,因為這些公司需要全面發展的人才。相較之下,大公司更需要專業領域的專才。大公司擁有完善的組織架構和專業團隊,在大公司工作通常會專注於特定領域的專業技能。與此相反,在小公司工作可能需要具備多樣化的技能和角色,並能夠靈活應對各種挑戰。小公司的組織結構相對扁平,這意味著你可能有更多機會與高層管理人員和決策者直接合作,能夠迅速發揮影響力。
講者提供了一些例子來說明大公司和小公司的不同經驗。在轉換到大公司工作的過程中,講者遇到了一個問題:ML研究員在特定的生產環境中需要安裝Java Package,但遇到了困難。由於講者具備廣泛的技能,只需要加上幾行程式碼就解決了這個問題。而在小公司工作的經驗中,講者需要在幾天內開發一個客戶要求的功能,以便在下個星期的會議中展示。但在小公司工作的另一個好處是組織扁平,容易發揮影響力,講者也經常直接與CTO合作。大公司的工作通常更加計劃性,需要與各部門協調進度和調度資源(例如前端、後端、資料工程等),這將呈現出不同的工作風貌。
顧問 vs 全職
講者認為顧問業是相對較少被探討的職業經驗之一。顧問業常見的工作方式是按照時間計費的方式承接專案。顧問在工作時間上有相對較多的彈性,但工作型態通常以計畫為基礎,根據專案開發所需的時程而定,可能持續數星期到幾個月之久。如果專案進度不穩定,或者專案被取消,可能會失去工作並影響收入。
相較之下,全職員工通常被公司視為人才培養對象,並提供各種訓練和資深成員的指導。講者過去在顧問業的經驗更加著重於實作甲方需求的功能,這對於技能的培養非常有效,同時也可避免職場社交的壓力。講者以前有朋友向其諮詢如何轉向其他相關領域發展,講者建議該朋友可以嘗試在顧問業中以約聘累積經驗。約聘通常容易找到工作機會,但同時需要具備快速適應新環境的能力,若是不能快速上手提出貢獻的話並且可能會在短期也內被裁掉。此外,大公司有時會尋找顧問來協助專案的開發進展。這通常需要與公司內部人員合作,並在一定的時限內完成專案。

從無經驗到有經驗,考慮替代職位 — 圖片來源 — 講者投影片 [7]
Pursue Relevant Certifications

從無經驗到有經驗 , 獲取相關經驗 — 圖片來源 — 講者投影片 [9]
在職涯的早期階段,講者透過創建許多 Side Project 來學習相關知識。像是Python 以及相關的 data science tech stack 。初期他在 Kaggle 平台上的學習進度極為迅速,原因在於他可以直接參考其他參賽者在 Kaggle 上的程式碼,這讓他能夠迅速地學習許多新知識。例如,他在 XGBoost 早期還在 Kaggle 初為人知時,就開始接觸學習了。但當時講者的作業環境是在 Windows 上,還需要掌握許多額外的知識才能成功編譯安裝 XGBoost ,直到後來掌握各種新技術像是 Windows Subsystem for Linux 開發才變又得更便捷。同樣的還有像是學習深度學習框架像是 Keras 與 PyTorch 的過程也是如此。
而現今有了 ChatGPT 等人工智慧輔助工具的存在後,學習過程可能會變得更快速。面對任何疑問,他都可以先向 ChatGPT 提問,以便更快獲得解答並釐清問題。
Networking
從無經驗到有經驗,方法四 — 社交聯繫 — 圖片來源 — 講者投影片 [10]
講者透過數個實例,闡述了建立社交聯繫對其職涯發展所帶來的影響。許多的社交聯繫在後來皆成為他開展職涯的關鍵。
在他的職涯初期,有幸由其國高中同學的同學介紹一位新創企業創辦人與並加入其領導的一項創業計畫,同時獲得了在美國的首份工作機會。然而,這並非全然依靠社交聯繫所得,而是透過社交聯繫進一步得到被看見的機會。仍然必須憑藉自身的技術、經驗與能力,才能通過面試的標準。講者回顧了自己在面試時展現出對資料科學領域的熱誠和專業知識,這也緩解了主管對他當時轉換職涯領域的疑慮。
另一方面,藉由參與相關興趣的社群活動,例如參加機器學習競賽,講者與其他參賽者建立連繫,從而學習到許多新的技術。例如,他是從一位新創公司的創辦者那裡初次接觸到 Docker 技術。經過這位創辦者分享的配置文件 (Config) ,講者對此技術產生了興趣,並開始增強自己的模型部署技巧,後來亦在Udemy 上找到相關課程進行系統性的學習。
最後,對於主持人提出的問題,即在社交場合中對陌生人主動接觸(cold approach)時的結果可能極端兩極化的現象,講者有如何處理?講者表示,由於缺乏先前的互動與共享經驗,許多隨機因素都可能影響建立連繫的結果。然而,善用社會證明(social proof)可以有助於獲得穩定的結果。社會證明是指人們傾向於依賴他人的行為和決策來指引自己的行為和決策,其中預選效應(preselection)則是社會證明的一種具體形式。這是指當其他人已經選擇與你聯繫時,你將更有可能在現場被新的陌生人所接受。因為他們看到其他人已經選擇了你,他們就認為你是有社交聯繫價值的人物。所以在社交聯繫現場時要努力建立與經營如此的形象。
金融產業中的資料科學應用
講者分享了一些自己在 Moody’s KYC所側重的專案方向,讓大眾可以更認識在金融業中有哪些Data Science 的應用。

KYC Data Solutions — 圖片來源 — 講者投影片 [11]
風險資料集以及風險洞察
- 主要透過收集從多種來源(包括政府、法院和商業組織)收集資訊,建立全面而深入的資料庫。這不僅需要資料工程技術的支持,也需要我們用資料分析技巧去理解和整理這些資訊。透過聚合分析來整合資訊,並從中提取有價值的洞察,以便提供給需要這些資訊的客戶。在商業模式方面,透過了解客戶的需求和痛點,並根據這些需求提供相關的資訊。比如,提供與客戶往來的實體有關其的監管資訊給需要遵守歐盟新監管規定的客戶;對於關注近期國際制裁情況的客戶提供與客戶往來的實體相關的制裁風險資訊。
- 在風險管理的領域中,風險評估的過程通常包含許多主觀和客觀的元素。風險評估的結果會受到審核方的風險觀念、風險接受度、市場理解、法規要求等因素的影響,往往各審核方之間的風險評估結果並不會完全一致。以大麻商品經營為例,某些金融機構(如銀行A)可能會認為此類業務具有相對較高的風險,因為它可能涉及到法律規定的灰色地帶,或者可能引起公眾輿論的關注。因此,這些金融機構可能會選擇不接受或者小心謹慎地處理這類業務。然而,另一些金融機構(如銀行B)可能對大麻商品的市場有更深入的理解,認為在特定的市場環境和法規框架下,這類業務可以是穩定並可持續的,因此不會給該銀行帶來過高的風險。因此,這些金融機構可能會更願意接受並支持這類業務。
客戶引入流程的工作流整合
這種解決方案提供一種少程式碼(low-code)或無程式碼(no-code)的平台,讓用戶可以根據自己的風險容忍度和內控流程,客製化自己的客戶引入(on-boarding)流程。這種工具的優勢在於其靈活性和易用性,即使是非技術人員也能輕易地利用它來設計和實施 KYC 流程。此外,一旦流程被設計並佈署,它就可以自動執行,從而節省人力,提高效率,並減少人為錯誤的可能性。在這裡,資料科學的運用是設計出各種模組,這些模組能提供深入的資料洞見。這些洞見是由前述的風險資料庫萃取出的資訊,經由資料科學或機器學習的方法處理資訊來提升其價值。
其他自然語言處理的應用
利用自然語言處理(NLP)中資訊豐富化(enrichment)建立內部工具來幫助分析師在風險分析的場景中,可以幫助分析師更有效地篩選和理解資訊。例如來自動標記新聞與報導中的關鍵資訊,例如地點、時間、人物、機構、事件等,這些 metadata 可以幫助分析師快速瀏覽和尋找他們感興趣的內容。例如,如果某些部門的分析師只對商用房地產的報導感興趣,我們可以使用這些工具去識別和過濾出這類相關的報導,比如說提供德州奧斯丁新建倉庫的資訊。
Entity Resolution / Record Linkage
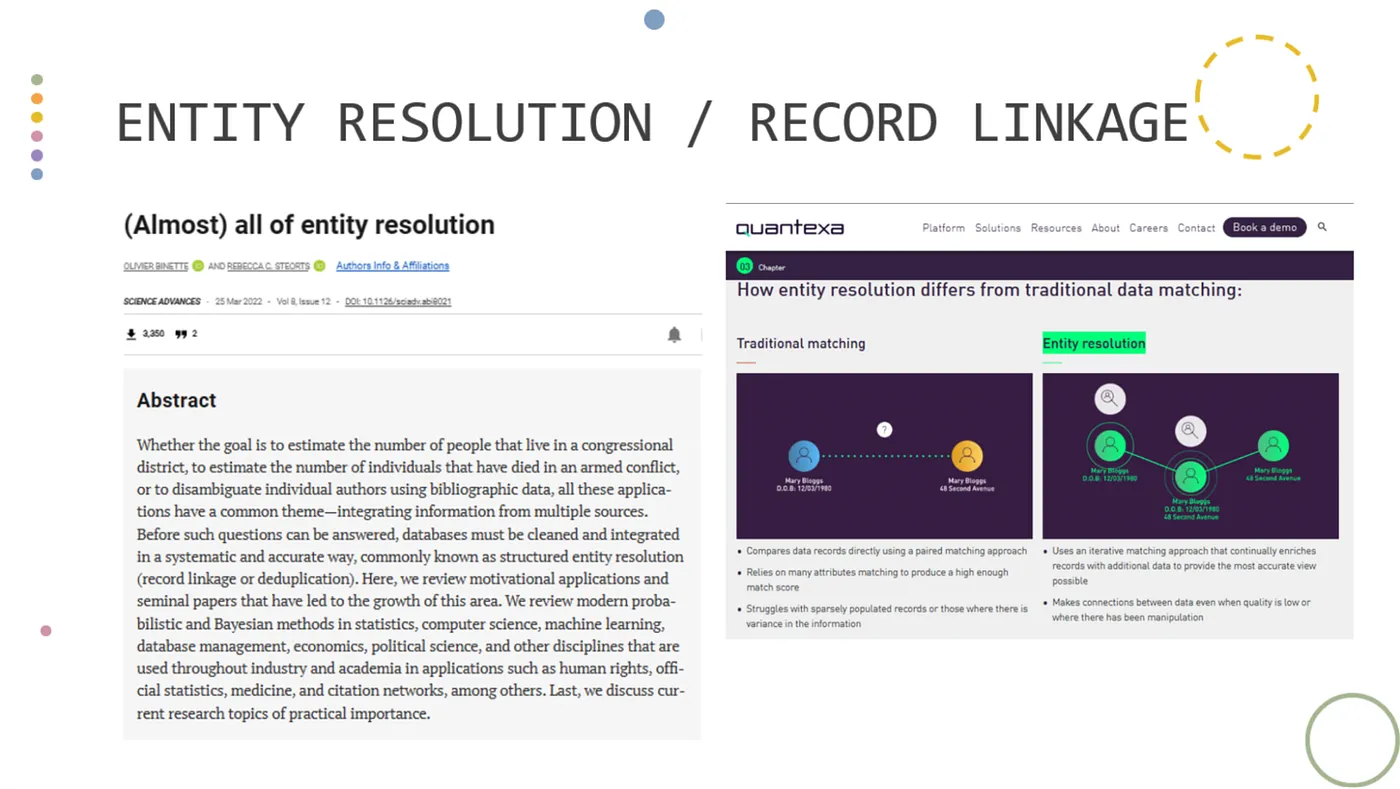
Introduction about entity resolution and record linkage — 圖片來源 — 講者投影片 [12]
講者指出,實體解析,雖然還是一個相對較新的技術,但在科學期刊的子刊中(左)已經看到許多關於此領域的研究和技術被詳細的回顧和整理。業界也廣泛地應用這項技術,甚至已有企業(右)提供了商業解決方案。其中,尤其在風險控管領域,實體解析顯現出其重要的價值。
在風險控管的過程中,能確定某個實體或個人的身份是否為同一人是非常關鍵的,特別是在處理跨資料庫整合時。實體解析的主要目標就是確認不同資訊來源中的同名實體是否指的是同一個人或事物。例如,如果有兩個名為“王大明”的客戶,實體解析就會根據他們其他的資訊(如地址、年齡、職業等)來判斷他們是否為同一人。在企業運作中可能同時有許多不同取向的實體資料庫,要藉由整合發揮這些資料庫的價值來創造更多的價值時,實體解析就更為重要。
假設有兩個不同的資料庫,一個是銀行的貸款申請資料庫,另一個是保險公司的理賠紀錄資料庫。這兩個資料庫都可能含有一位名為”王大明”的客戶。雖然他們的姓名相同,但由於這兩個資料庫的目的不同,所以無法確定他們是否為同一人。這時,以使用實體解析技術來整合這兩個資料庫的資訊。如果這兩個”王大明”是同一個人,那麼我們就可以將他在兩個資料庫中的資訊整合起來,例如他的貸款申請情況和理賠紀錄,以此來對他的風險進行更全面的評估。反之,如果他們不是同一個人,則可以將他們的資訊分開處理,避免將一個人的風險錯誤地歸咎於另一個人。這樣的例子顯示了實體解析在風險管理中的價值。透過實體解析,我們可以將來自不同資料庫的資訊連結起來,讓我們對風險有更全面、更準確的了解,從而做出更好的風險管理決策。
這與命名實體識別(NER, Name Entity Recognition)技術有所不同。NER能識別出文本中的具有特定意義的信息,如人名、地名、機構名等。但其局限在於,它無法確定識別出來的實體是否為同一個人或事物。換句話說,即使使用 NER 技術可以從不同的文件中找到名為王大明的人,但我們無法確定他們是否為同一個人。而實體解析則可以將來自不同方面的資訊整合到同一個實體上,使對實體的風險判定更為準確。
QA精選
Q1 : 想請教講者,轉職學習中,通常自己想信要花 10 小時學習,但最後真的學好,可能其實花了 100 小時,關於這當中的 Gap ,有建議什麼心態調整的方式
A:講者認為有兩個方式可以參考:
- 利用原子習慣的方法,首先制定清晰且易於實現的目標,並將其分解為更小的可行步驟。專注於建立持續的學習習慣,而不僅僅是追求一次性的成果。保持耐心並接受學習過程中的挑戰,認識到長期努力才能帶來真正的成果。把事情切的很小很小,讓每件事都可以完成,就可以持續累積成就感。
- 另外現在可以善加利用ChatGPT來加速學習的迭帶速度 ,透過妥善利用ChatGPT等資源,實踐過程中的困難度可能會降低,從而提高學習效率,可能也不會花費太多時間在實現和除錯上。
Q2 : 線上課程的認證與 Kaggle 參賽的成果(排名)等等經歷,寫在 CV 裡真的有助於找資料科學相關工作嗎?反過來問,資科公司的 hr 會去在乎這些經歷嗎?
A :在筆者的面試與被面試的經驗中,Kaggle 參賽成果和線上課程認證的確可以在一定程度上幫助求職者找尋資料科學相關工作。
- Kaggle 參賽會放在履歷上,可以做為面試中的談資。 Hiring Manager 確實會看有興趣的話會進行一些討論。可以據此準備一些話題,但比較像錦上添花,如果沒有實務工作經驗,是聊勝於無的話題。當然如果有傑出的成果被問起的時候,也可以深入討論自己對問題的思維與解法。
- HR 在 LinkedIn 上招聘時會參考求職者檔案中取得的線上課程認證來決定是否適合手上的職缺。
Q3 : 請問 junior 工程師在美國有年齡上限嗎?
A 講者就親身數個經驗觀察在美國,Junior 軟體工程師並不見得有明確的年齡上限.講者有一位軟體工程師同事,先前是律師,工作多年後修習資訊工程碩士學位後轉職為 Junior 軟體工程師。另外也有數位在家庭中待了幾年的資料分析師等,之後也成功重返職場。事實上,無論是初級或高級職位,講者認為年齡在美國就業市場中並未受到過多的重視。
Q4 : 對非本科系, 究竟應該從基礎學科(線性代數, 統計學)開始學起, 還是建議直接學資料科學實務(如 python, ML )相關的課程呢?
A :如何選擇學習方向主要取決於個人的職涯目標。大致可以分為以下兩類:
- 資料科學家:理論與實務兼顧,並且理論基礎要相對扎實,能夠對各種不同知識水平的其他利害關係人深入淺出解釋數據驅動背後的學理背景。
- 工程師:實務技能更為重要。在學理上,擁有所謂的工作基本知識 (working knowledge) 是非常重要的。這意味著他們需要具備足夠的實務技能和對相關領域的基本理解,以便能夠在工作中解決實際問題和有效地完成任務。
Q5 : 會覺得跟科技業相比金融業相對穩定嗎,工作會不會比較不容易受景氣影響?
A :其實很難講,科技業今年第一季,領頭的科技巨頭帶頭幾波裁員,像是Meta, Google, Amazon 等大大小小的科技業都進行了裁員。因其裁減成本的作為容易獲得華爾街分析師的青睞並調升其股價預期。另外前一陣子,金融業目前還是有蠻多公司的狀況不好,比如三月的矽谷銀行擠兌,UBS 併購Credit-Sussie,以及 First Republic Bank。未必像是大家所認為現下的經濟情勢中銀行業相對穩定,僅僅是科技業面臨科技業寒冬。
Q6 : 進修的方向如何選擇
A: 講者在選擇進修方向時,主要根據自己的工作需求來制定學習計劃。講者偏好實際操作(on-hand)的課程,因此會挑選那些可以實際動手操作和應用的課程。
Q7 : 在金融業做 model, 相較於其他行業,有需要特別做什麼樣的事來達到合規呢?
A :講者表示自己的工作經驗主要涉及資料科學領域的模型,對一般的財務和金融模型相對不太熟悉。然而,在金融業進行模型建構時,需要遵循數據治理(data governance)和模型治理(model governance)的規範。這可能包括提供技術文件、訓練方法和驗證方式等。然而,這並不意味著必須提供完整的實作細節,否則客戶可能有機會實作出類似的產品。對於其他方面,如合約、軟體上的 SoC2(Service Organization Control 2)以及政府法律要求,講者相對缺乏經驗。
Q8 : 請問可以分享公司對於每一個新產品的分析結果,大多會多久之後開始take action 呢 謝謝
A: 就講者目前的經驗,在開發的過程上歷經先有概念驗證(PoC)→ 最小可行性產品(MVP)→ 最小市場可能產品(MMP)→ 招募 alpha/beta 客戶並獲得回饋 → 正式產品發表。在大公司中,部門分工精細且環環相扣。例如,若計劃在年度內為業務團隊提供足夠的時間進行銷售培訓,則需要在第二季度完成初步開發,以便在下半年開始向客戶推廣產品。因此,實際採取行動的時機取決於公司的組織結構、產品開發流程和市場需求。
Q9 : 我是 MLE 最近從 CV 跨到做廣告轉換 不知道這樣的轉換會不會是職涯上的缺點, 也想知道你的看法
A :講者認為可以嘗試進行這這類的轉換。在相近領域之間轉換職業軌道,有失去累積技術深度的機會但同時也有拓展領域知識的廣度。實際上,廣告業仍然存在應用 CV 技術的場景,因此之前累積的知識和技能也有機會移轉在新領域得到應用。然而從長遠來看,還需要思考自己希望成為哪種類型的MLE,以確保職業生涯發展符合自己的興趣和目標。
筆手 : Joe Tsai
校稿:Ting Yu,Chia-Ta Tsai
👉 歡迎加入台灣資料科學社群,有豐富的新知分享以及最新活動資訊喔!